
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 머신러닝
- 빅데이터처리
- NLP
- AI
- 데이터처리
- SQL
- ggplot
- HIVE
- Python
- 데이터시각화
- 그래프
- R그래프
- R시각화
- 그래프시각화
- 데이터분석
- R프로그래밍
- lstm
- word2vec
- Hadoop
- CNN
- pandas
- r
- Deeplearning
- 주가예측
- 하둡
- 딥러닝
- 기계학습
- 빅데이터
- 데이터
- 자연어처리
- Today
- Total
욱이의 냉철한 공부
[SQL실무] SQL vs EXCEL : 차이점, group by, subquery, case, join문 등 본문
[SQL실무] SQL vs EXCEL : 차이점, group by, subquery, case, join문 등
냉철한 욱 2020. 4. 17. 00:21SQL에서의 작업과 EXCEL에서의 작업을 비교해보고자 합니다!
1. SQL 작업
2. EXCEL 작업
SQL 작업에서는 제가 인턴하며 실무에서 많이 사용했던 구문들을(group by, subquery, case when, join)
적용하도록 하겠습니다.
1. 작업설명
1) 테이블 설명
SQL 예시 테이블로 DEPT, EMP, SALGRADE를 많이 사용하죠.
이 테이블들은 부서마다 직원의 봉급을 나타낸 테이블입니다.
저 역시 이 테이블로 작업을 해보도록 하겠습니다.
다만 이 작업에서 제가 사용할 테이블은 EMP, SALGRADE 입니다.
아래와 같습니다.
* EMP

* SALGADE

2) 작업설명 : 문제
해야 할 작업은 직무, 등급별로 직원들의 봉급 총합계를 구하는 것입니다.
(그런데 등급명을 숫자에서 영어명으로 변경을 했고,
PRESIDENT의 봉급은 1000 올렸습니다.) => 이 부분이 데이터를 처리해야하는 과정이 되겠죠!
정답 테이블을 한 번 봐볼까요.
* 정답 : MSSQL

* 정답 : EXCEL

자 이제 한 번 작업(문제)를 해결해봅시다.
2-1. 문제해결 : SQL
0) 전체 개요

이렇게 쿼리를 작성하여 결과를 도출 할 수 있었습니다.
물론 pivot 함수, 계층함수등을 활용해서도 쿼리를 작성할 수 있는 것으로 알고 있습니다.
하지만 이 쿼리가 정석같은 느낌이기 때문에
또 자주 사용하는 SQL문들을 설명할 수 있기 때문에,
이 쿼리로 설명하도록 하겠습니다!
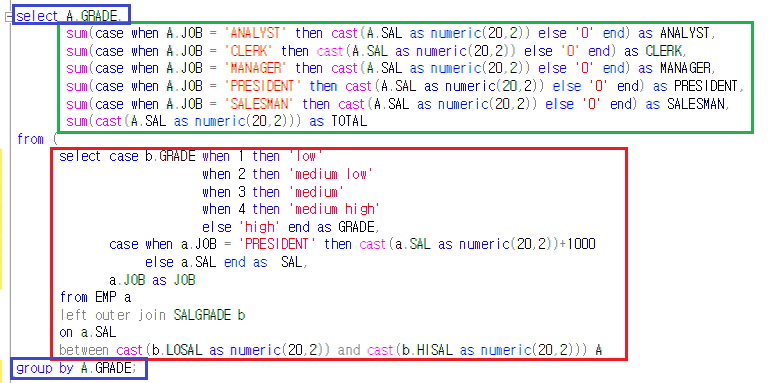
중요한 부분을 3부분으로 설명할 수 있습니다.
from절의 빨간색 박스부터 살펴보도록 하겠습니다.
빨간색 -> 파랑색 -> 초록색 순으로 쿼리를 작성했기 때문입니다.
* 왜 빨간색-> 파랑색 -> 초록색 순서인가?
효율적인 쿼리 작성 순서는
FROM(빨간색 박스) -> WHERE -> GROUP BY (파랑색 박스)-> HAVING -> SELECT(초록색 박스) -> ORDER BY
입니다.
왜냐하면 이 순서대로 쿼리가 작동하니깐요.
1) 빨간색 박스(from절) : Subquery(인라인뷰), Join문 활용
빨간색 박스안에 또 다른 쿼리문(select ~ from) 즉 서브쿼리가 작성되었습니다.
from절 안에 작성된 이 서브쿼리는 인라인 뷰라고 명칭합니다.
인라인뷰의 서브쿼리에서 특이사항은 조인을 한 새로운 테이블을 만든다는 것입니다.
이 인라인뷰의 서브쿼리만 확인해보겟습니다.
아래 보시면 원래의 "EMP" 테이블에서,
"SALGRADE"테이블과 JOIN된 "인라인뷰"테이블을 확인하실 수 있습니다.
- 빨간색 박스의 Subquery

- EMP와 SALGRADE가 JOIN된 테이블

=> JOIN : left outer join 구문 활용 설명
"EMP"테이블에서 'SAL'열을 "SALGRADE"테이블의 'LOSAL', 'HISQL'열과 조인(참조)을 하였습니다.
기준 열은 당연히 'SAL'열이 되며, 'SAL'열은, 어느'LOSAL', 'HISQL'열 값 사이에 들어가는지 비교되어집니다.
비교 결과에 따라 최종적으로 "EMP"테이블에 "SALGRADE"테이블의 'GRADE', 'LOSAL', 'HISQL' 열이 새롭게 추가됩니다.
이렇게 추가되어 새롭게 완성된 테이블이 "join된 인라인뷰"테이블이 되겠습니다.
* Nonequijoin
위 join처럼 값('SAL')이 일치되어지는 것이 아닌, 소속되어지는 join을
equijoin이 아닌 Nonequijoin이라고 합니다.
- 이후 전처리된 최종 인라인 뷰
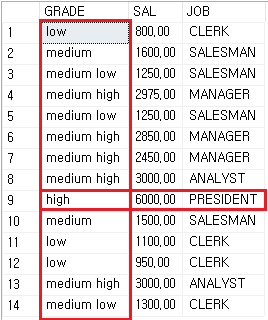
=> 전처리 : case when 구문 활용 설명
"EMP와 SALGRADE가 JOIN된" 테이블에서 'GRADE'열을 case when 구문을 활용하여, 영어명으로 바꿨습니다.
더불어 'JOB'열이 PRESIDENT인 경우는 SAL을 1000 올렸습니다.
이 부분이 데이터에서 전처리가 필요한 부분이 되겠습니다.
* case when 구문
case when문은 if문과 동일한 목적으로 사용합니다. 구문도 비슷합니다.
case when문에서 조건이 많을 경우에는 2가지 방식으로 활용합니다.
1번재 활용
case when 조건1 then 출력결과
when 조건2 then 출력결과
else 출력결과
=>
case when job ='clerk' then "점원"
when age = 20 then "신입생"
else "백수"
2번째 활용
case 조건 when 조건결과 then 출력결과
when 조건결과 then 출력결과
else 출력결과
=>
case job when 'clerk' then "점원"
when 'salesman' then "영업맨"
else "백수"
주로 조건에 여러 열을 사용할 경우 첫번재 방식을 활용합니다.
조건에 한가지 열을 사용할 경우에는 2번재 방식을 활용합니다.
2) 파랑색 박스(Group by절) : Group by 활용

=> 그룹핑 : group by 구문 활용 설명
쿼리문 작성에서 가장많이 활용되는 문이라고 생각합니다.
이 쿼리에서는 'GRADE' 열별로 그룹을 나누는 것입니다.
이 열이 select절의 기준 즉, 'A.GRADE'가 됩니다.
'A.GRADE' 기준으로 그룹을 나누었으니, 각 그룹별로 계산된 값들이 select절에서 나와야겠죠?
그 계산된 값을 도출하는 함수를 집계함수라고 합니다.
이 쿼리문에서는 sum함수가 되겠습니다.
3) 초록색 박스(Select 절) : Case문 활용

=> 최종집계 : case when 활용 설명
세로 열에 각 직업별로 그룹핑하고자 이렇게 각각 case when 문을 작성하였습니다.
생성된 첫번재 열 'ANALYST'를 확인해보자면
"GRADE"열별로 나누어진 직원들의 "SAL"열 봉급은
"JOB"열별로 합산되어집니다.
이 "JOB"으로 그룹핑된 결과는 새롭게 세로열로 표현되게 되어집니다.
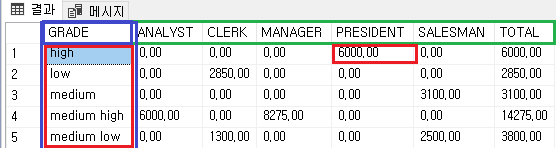
4) 결과
그리하여 최종 결과를 보시자면,
2-2. 문제해결 : EXCEL
0) 기존 테이블
- EMP 테이블

- SALGRADE 테이블
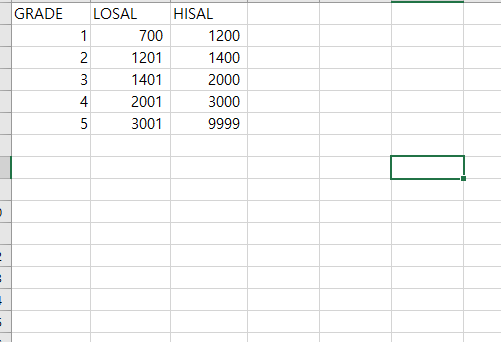
1) SQL에서 빨간색 박스(from절) 이었던 부분
- EMP와 SALGRADE가 JOIN된 테이블

=> JOIN : MATCH 함수 활용
"EMP"테이블에서 'SAL'열은 "SALGRADE"테이블의 'LOSAL'열을 참조습니다.
기준 열은 당연히 'SAL'열이 되며, 'SAL'열은, 어느 'LOSAL'값과 비교되어집니다.
비교 결과에 따라 최종적으로 "EMP"테이블에 "SALGRADE"테이블의 'GRADE' 열이 새롭게 추가됩니다.
* MATCH 함수 사용방법
MATCH 함수 사용방법은 아래 블로그에 자세히 나와있습니다. 참고하시면 좋을 듯 합니다.
https://blog.naver.com/011mins/220469463158

- 전처리 : GRADE 변경

=> 전처리 : 필터 활용 (단축키 : Ctrl+Shift+L)
- 전처리 : PRESIDENT의 SAL 값 변경
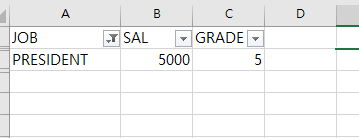
=> 전처리 : 필터 활용 (단축키 : Ctrl+Shift+L)
- 이후 전처리된 최종 테이블

2) SQL에서 파랑색 박스(Group by절), 초록색 박스(Select 절) 이었던 부분

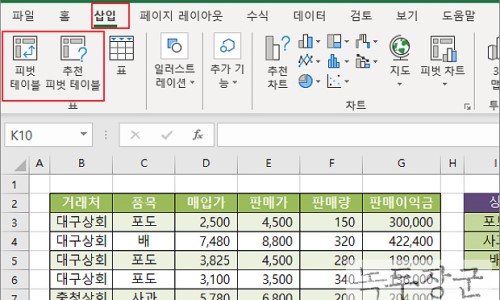
=> 최종집계 : 피벗테이블 활용
피벗테이블을 활용하여 이렇게 GRADE, SAL열 동시에 그룹별 집계를 쉽게 산출할 수 있습니다.
그리하여 SQL로 도출한 최종테이블과 동일하는 것을 확인 할 수 있습니다.
* 피벗테이블 사용방법
피벗테이블 사용방법은 아래 블로그에 자세히 나와있습니다. 참고하시면 좋을 듯 합니다.
https://mainia.tistory.com/2296
4) 결과
그리하여 최종 결과를 보시자면,

=> SQL로 도출한 최종테이블과 동일!
* SQL vs EXCEL의 차이점
(추후 수정)
지금까지 2회사에서 인턴하면서,
EXCEL과 SQL을 많이 사용할 수 있었습니다.
SQL에서 수천만 데이터를 엑셀에서도 수십만 데이터를 처리할 수 있었는데요.
사실 EXCEL, SQL의 주목적인 "데이터 처리"는 동일하다고 생각합니다.
하지만 각각 특징이 있겠죠? 경험을 기반하여 "데이터 처리" 측면에서만 구분해보겠습니다.
- SQL
대용량 데이터 처리 가능.
작업자들과 공유 수월.
DB언어 즉 여러 개발언어와 연계가능
- EXCEL
대용량 데이터 처리 불가
속도 매우 느림
하지만 작업방법 매우 간단 (피벗테이블이면 모든 것이 해결)
경험상 가장 큰 차이는 데이터 양의 수용성인 듯 싶습니다...
'데이터엔지니어링 > 구조형데이터 : SQL' 카테고리의 다른 글
| [MS-SQL] 문법정리 (0) | 2020.04.16 |
|---|
