
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- R프로그래밍
- ggplot
- 머신러닝
- 그래프시각화
- 빅데이터
- Python
- NLP
- r
- lstm
- 데이터처리
- 데이터시각화
- CNN
- AI
- Deeplearning
- 데이터분석
- Hadoop
- 데이터
- HIVE
- 자연어처리
- 주가예측
- pandas
- 빅데이터처리
- 딥러닝
- R시각화
- R그래프
- 하둡
- 기계학습
- word2vec
- 그래프
- SQL
- Today
- Total
욱이의 냉철한 공부
[논문 요약] Deep Learning for Stock Prediction Using Numerical and Textual Information, 2016 본문
[논문 요약] Deep Learning for Stock Prediction Using Numerical and Textual Information, 2016
냉철한 욱 2020. 4. 20. 03:12* 논문
Deep Learning for Stock Prediction Using Numerical and Textual Information, 2016
* 목차
1. 입력데이터
2. 출력데이터
3. 모델링
4. Trading simulation
5. contribution
6. 한계점
0. 방향성
Many of previous works used only one of textual, numerical, or image information for stock price prediction, and their model was trained with consideration about a single company.
Nevertheless, it is desirable for the prediction model to consider multimodal information and multiple companies at the same time since investors make decisions depending on various factors such as relationships between companies.
1. 입력 데이터
- 입력 데이터 대상
일본 기업 (10개) : 데이터 수집 기간에서 가장 빈번하게 뉴스기사가 나오는 기업 10개 선정. (같은 산업분야)
이 10개 기업은 Nikkei 225에 소속된 기업.
=> 하나의 모델링 설계
=> 10개의 기업은 같은 산업분야로서 서로간의 상관관계를 학습할 수 있게 모델링 설계.
- 입력 데이터 종류 : 일 단위
1. 정량적데이터(거래데이터) : 시가
2. 텍스트데이터 : 뉴스기사
- 입력 데이터 출저
1. 정량적데이터(거래데이터) : Nikkei Newspaper
2. 텍스트데이터 : Nikkei Newspaper
- 입력 데이터 기간
1. 정량적데이터 : 2001 ~ 2018
2. 텍스트데이터 : 2001 ~ 2018
- 입력 데이터 분류
1. Total DatatSet : 2001 ~ 2018
2. Training DataSet : 2001 ~ 2006, 약1440개
3. Validation DataSet : 2007
4. Test DataSet : 2008
- 입력 데이터 벡터화
1) 정량적데이터 : 시가
1. 각각 10개 회사의 시가데이터를 정규화한다.
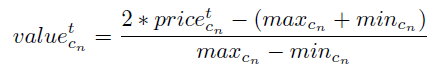
2. 각각 10개 회사의 Value(t)값을 Concatenate하여 벡터 n(t)를 만든다.
2) 텍스트데이터 : 뉴스기사
1. 수집된 10개 회사의 뉴스기사를 PV-DM, PV-DBOW 임베딩 기법을 사용하여 벡터화 한다.
2. 각각 10개의 회사의 벡터를 Concatenate하여 벡터 p(t)를 만든다.

=> 하루(하나의 time step)에 뉴시기사가 없는 경우 0 기입.
=> 하루(하나의 time step)에 많은 뉴스기사가 있는 경우 그 날 뉴스기사들의 평균 기입.
- 입력 데이터 차원 표현 (Training set 기준)
1. 정량적데이터 n(t) : (1440, 10, 1) =>(1440, 10)
=> 1440일에 10개의 회사에, 각 시가를 벡터 표현
2. 텍스트데이터 p(t) : (1440, 10, 100 * 2) => (1440, 2000)
=> 1440일에 10개의 회사에, 각 뉴스기사를 임베딩 기법을 통해 각 200차원으로 벡터 표현
=> PV-DM으로 100차원, PV-DBOW으로 100차원
2. 출력 데이터
- 출력 데이터 종류
종가
- 출력 데이터 기간 : Delay
종가 : 당일
- 학습(최적화) : 손실함수
가격예측(Regression)하는 모델 : RMSE
3. 모델링
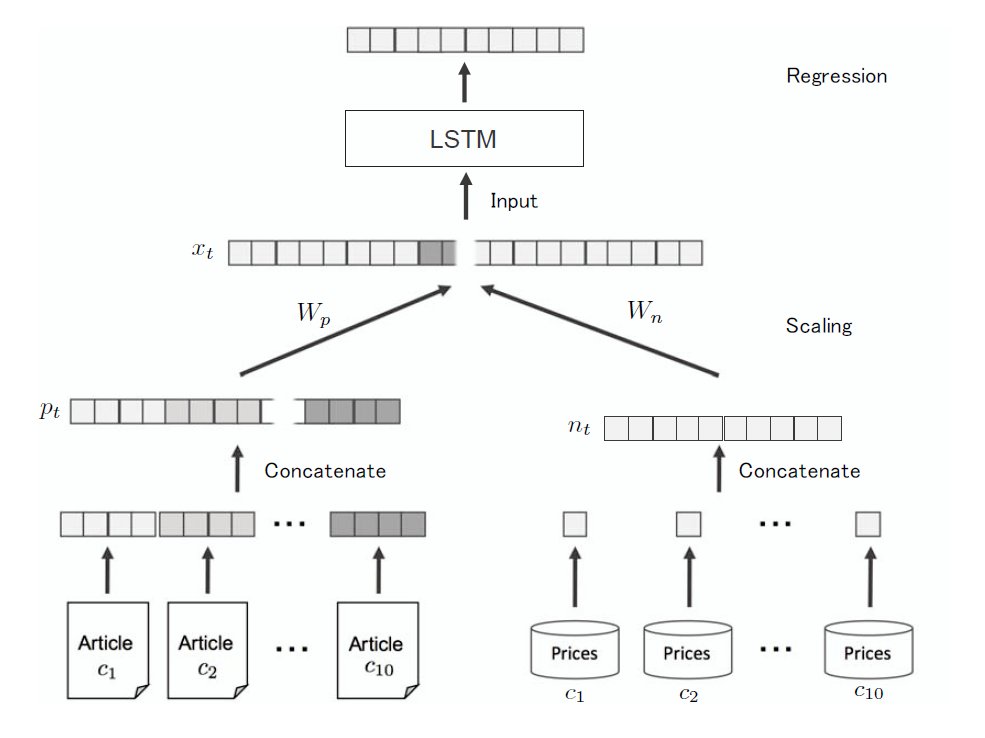
1. Scaling 단계
LSTM 모델에 투입되는 input인 X(t)은 앞 서 설명한 그룹벡터 p(t)와 n(t)를 조합(Scaling)하여 만들어진다.
=> n(t)는 일반적으로 p(t)보다 더 많은 차원을 가지고 있다.
이것은 LSTM 모델을 무겁게 만들고, 성능을 떨어트린다.
그리하여 n(t)와 p(t) 같은 차원으로 조합하기 위해 Scaling작업을 가진다.
즉 n(t), p(t)의 차원을 동일하게 만들고, Concatenate하여 X(t)의 차원인 dx가 된다.
이 Scaling 작업을 위해 neural network를 사용한다.
이를 통해 주가예측을 위해 중요한 정보(feature)만 추출하는 것을 기대할 수도 있다.

=> LSTM의 Input으로 들어갈 X(t)의 차원은 P(t)와 N(t)가 Concatenate하여 만들어진다.
P(t)는 기존 p(t)의 (1440, 2000)에서 (1440, 500)으로 Scaling 작업을 통해 바뀌어진다.
N(t)는 기존 n(t)의 (1440, 10)에서 (1440, 500)으로 Scaling 작업을 통해 바뀌어진다.
P(t) (1440, 500)과 N(t) (1440, 500)는 Concatenate되어 x(t) (1440, 1000)이 된다.
2. Neural Network로 추출된 날짜별 1차원 배열 X(t)는 LSTM의 input으로 투입된다.
=> LSTM을 쓰는 이유는 input의 순서적 features들의 영향을 보존하기 위해서이다.
4. Trading simulation
- Trading 기간
test data 기간
- Trading 초기값
거래비용은 회사당 최대 1,000,000yen으로 제한
- Trading 방법

1. 당일 오전 시가보다 예측한 오후 종가가 더 높으면, (수익이 2% 이상)
오전에 주식 구매하고 오후에 판매한다.
2. 당일 오전 시가보다 예측한 오후 종가가 더 낮으면, (수익이 -2% 이상)
오전에 주식 판매하고 오후에 구매한다.
5. Contribution
1. Paragraph Vector의 효과가 있다.

2. LSTM의 효과가 있다.
=> 변동성 있는 시간적 변화를 나타내는 feature들을 잘 붙잡는다.
Since LSTM, being nondeterministic transaction got higher profits, it was assumed that LSTM was able
to capture the fluctuating time series changes well.

3. 같은 산업군의 다양한 회사들을 고려하는 효과가 있다.
6. 한계점
향후 작업의 경우, 더 나은 수익 창출 능력을 위해 이동 평균(MA)과 이동 평균 융합 다이버전스(MACD)와 같은 더 많은 기술 지수를 도입하고 싶다.


