
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 머신러닝
- word2vec
- 빅데이터
- lstm
- R프로그래밍
- 데이터
- HIVE
- R시각화
- 빅데이터처리
- 데이터분석
- 기계학습
- pandas
- 하둡
- 주가예측
- AI
- 데이터시각화
- NLP
- 자연어처리
- SQL
- 그래프시각화
- R그래프
- 딥러닝
- ggplot
- Deeplearning
- Hadoop
- r
- CNN
- Python
- 그래프
- 데이터처리
- Today
- Total
욱이의 냉철한 공부
[R, 데이터 실생활 응용] R로 카카오톡 활동량 분석하여 시각화. 본문
EPL 맨유 팬인 저는 카카오톡 맨유 팬 채팅방에서 활동하고 있는데요.
20명 가량의 이 방에서 누가 톡을 가장 많이 입력하는지,
즉 채팅활동을 누가 활발하게 하는지 R로 한 번 알아볼께요~!



매달 누가 채팅을 많이 했는지 빈도수를 계산하여 그래프를 만들어 올리고 있어요
(제 이름 제외하고 이름은 모두 지웠습니다.)
그럼 어떻게 만드는지 확인해볼 까요?
1. 카카오톡 채팅 방 설정에 대화내보내기 기능이 있다. 카톡내용을 텍스트형식으로 컴퓨터에 저장한다.
2. 저장한 텍스트형식 파일을 확인한다.

- 저장한 txt 파일을 열어 확인해 본다.
- 위에 보이는 것처럼 닉네임, 시간, 채팅내용이 순서대로 기록되어있다는 것을 확인 할 수 있다.
- 이 파일을 다시 저장하는데 인코딩을 ANSI로 설정한다. (한글이 R에서 받아들이기 위해서에요)
3. 코딩 - R에서 파일을 불러들어 단어별로 Count 한다.

- library(KoNLP)
extractNoun 함수를 사용하기 위해서 KoNLP 패키지를 활성화한다.
- useSejongDic()
세종사전을 사용함을 알려준다. 이 사전을 이용하여 extracNoun이 한글 명사를 추출한다.
- mergeuserDic(data.frame("[욱]","ncn"))
사람이름은 사전에 입력이 안되어있기 때문에 등록한다.
위에 txt 파일을 보면 욱이 아닌 [욱]으로 되어있다.
또 그냥 욱이라고 하면 채팅 글의 채팅내용에서의 욱과 중복될 수 있다.
- txt<-readLines("kakao2.txt")
채팅내용 파일을 R로 불러와 txt 변수에 저장한다.
* 왜 readLinse를 사용?
=> readLines 는 한 줄씩 읽어들어 큰 벡터 타입으로 만든다. -> sapply 함수를 사용하기 위해서이다.
-place<-sapply(txt,extractNoun,USE.NAMES=F)
* sapply
sapply는 벡터 혹은 리스트에 있는 각각의 원소에 특정 함수를 적용하기 위해서 사용한다.
txt 파일의 각 문장을 하나의 벡터 원소로 간주하여 특정 함수를 적용 할 것이다.
*extracNoun
sapply가 적용하는 특정 함수는 extracNoun이다.
extracNoun 함수는 한글을 입력 받아서 명사를 추출한다.
*USE.NAMES = FALSE
TRUE라면 문자형인 경우 함수 적용 결과가 txt에 나타나고 FALSE면 나타나지 않고 보존된다.
- wordcount<-table(unlist(place))
sapply결과가 리스트이기 때문에 벡터 형태로 만든다.
table 자료구조로 바꾼다. -> 각 벡터의 개수를 세어준다. 즉 table형태로 바뀌면서 명사를 Count 한다.
- head(sort(wordcount,decreasing = T),200)
상위 200개를 개수가 많은 명사부터 차례대로 보여준다.(내림차순)

- 시간도 기록되어 있기 때문에 숫자가 유난히 많다.
(숫자를 제외하는 함수가 있지만, 여기는 사람명사를 찾는 것이 중요하기에 딱히 숫자 결과가 있어도 중요하지 않다.)
- [욱]은 512번 채팅을 입력했다는 것을 확인 할 수 있다. (다른 사람들 이름은 보호하였다.)
4. 코딩 - 그래프 기리기
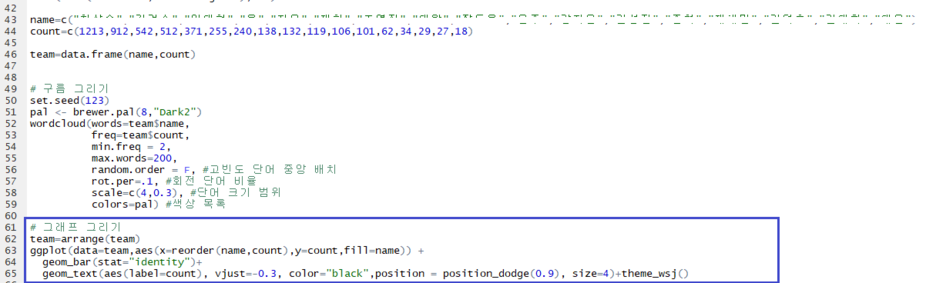
- 우선 필요한 데이터(사람이름과 Count한 수)를 확인한 후 새로 DataFrame을 만들었다.
(시각화 하기에 가장 좋은 자료구조는 DataFrame이다.)
- ggplot2 패키지의 geom_bar함수를 활용하여 막대그래프를 그렸다.
* ggplot(data=team,aes(x=reorder(name,count),y=count,fill=name))
team 데이터프레임을 바탕으로 x축은 name 그리고 y축은 count를 사용한다.
reorder() 함수를 사용하여 그래프를 그렸을 때 내림차순으로 시각화하게 한다. count기준으로 name을 정렬한다.
fill 인자는 name별로 색깔을 자동으로 입힌다.
* geom_bar(stat="identity")
막대그래프를 그린다. stat="identity"는 만약 레벨별로 막대가 나눠진다면 누적시키지 않는다.
* geom_text(aes(label=count), vjust=-0.3, color="black", position=position_dodge(0.9), size=4)
count를 막대그래프 위해 그린다.
vjust와 position인자는 위치 조정이다.
szie인자는 크기 조정, color인자는 색깔 조정이다.
* theme_wsj()
ggthemes패키지에 있는 함수이다.
배경색을 이쁘게 시각화해준다.

=> 이쁘게 막대그래프가 그려져 누구나 보고 쉽게 이해 할 수 있다.
본인은 512번의 채팅을 했었으며, 당시 채팅방에서 4번째로 많이 톡을 했다는 것을 알 수 있다.
'데이터분석 > R' 카테고리의 다른 글
| [R, 정리] 파일(csv, txt) 가져오기 (0) | 2021.06.22 |
|---|---|
| [R, 정리] 데이터 타입 이해하기 (0) | 2021.06.22 |
| [R, 정리] 기본 명령어 이해하기 (0) | 2021.06.22 |
| [R, 전처리, 패키지] sqldf 패키지 이용하여 R에서 SQL을 사용하자 (0) | 2021.06.22 |
| [R, 정리] R의 특징과 장점, 사용이유 (0) | 2021.06.22 |


