
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 주가예측
- 빅데이터
- SQL
- pandas
- R그래프
- R시각화
- 데이터시각화
- word2vec
- Python
- r
- 그래프시각화
- lstm
- CNN
- 자연어처리
- NLP
- 데이터분석
- 하둡
- 그래프
- ggplot
- HIVE
- 데이터
- Hadoop
- 딥러닝
- 기계학습
- 빅데이터처리
- 머신러닝
- 데이터처리
- AI
- R프로그래밍
- Deeplearning
- Today
- Total
욱이의 냉철한 공부
[R, 전처리, 패키지] dply패키지 사용하여 데이터 처리하기 본문
1. dplyr 패키지는 무엇인가?
1) plyr 패키지
데이터의 분할(split) – 적용(apply) -재조합(combine)하는 세 단계로 데이터를 처리하는 함수들을 제공하는 패키지이다.
대표함수 : adply(), ddply(), mdply()
2) dplyr 패키지
dataframe과 plyr이 합쳐진 이름으로 data.frame 전용 plyr 패키지이다.
대표함수 : filter(), select(), mutate(), summarise(), arrange()

3) dplyr 함수 구조
- 함수명()
- filter(iris, Species=="virginica")
- 첫 번째 인자는 dataframe
- 두 번째 인자는 dataframe으로 무엇을 할 지를 표현(조건)
- 반환값은 dataframe이다.
2. 기본 함수 사용 예시
1) filter() : 기준(조건)에 맞는 행을 선별한다.


- 보기의 편의성을 위하여 head()함수를 사용하였다. 앞의 6행만 출력한다.
2) select() : 이름으로 열을 선별한다.


- 출력값이 2번째 인자에 조정된 열이라는 것을 확인 할 수 있다.
3) arrange : 행을 기준열에 맞게 정렬한다.

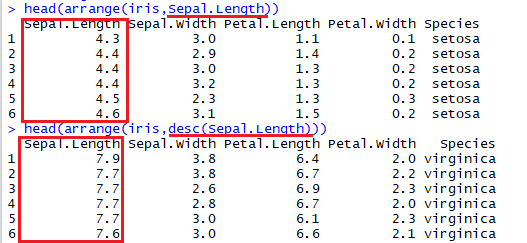
- 1번째를 보면 iris 데이터에서 Sepal.Length 열을 기준으로 정렬 된 것을 확인 할 수 있다.
- 2번째를 보면 iris 데이터에서 Sepal.Length 열을 기준으로 내림차순 정렬 된 것을 확인 할 수 있다.
- 내림차순 함수는 desc()이다.
4) mutate : 새로운 변수를 추가한다.


- doublePw이라는 새로운 변수가 추가 되었다는 것을 확인 할 수 있다.
- doublePw열의 값들은 Petal.Length의 값들에서 2 곱한 값이다.
5) summarise() : 변수들을 특정 값으로 변환한다.


- total이라는 새로운 열을 생성해서 해당 열만 출력한다.
- total 값은 iris데이터의 Sepal.Lenght열 값들의 합이다.
3. Join 함수
1) dplyr패키지의 Join 함수

- 해당 데이터셋은 본인이 임의로 만들었다.
- x와 y 데이터프레임에서 같은 열은 name이다.
- donguk, minyoung, eunsub, heagun이라는 값이 서로 겹쳐 있다.
left_join : x에 있는 모든 행이다. x,y열 모두 출력된다.
inner_join : y에 있는 x의 행이다. x,y열 모두 출력된다.
full_join : x와 y의 모든 행이다. x,y열 모두 출력된다.
semi_join : y에 있는 x의 행이다. x열만 출력된다.
anti_join : y에 있지 않는 x의 행이다. x열만 출력된다.
by 인자를 통해 병합 기준 열을 정한다.


2) 기본 함수 merge()
- by 인자를 통해 병합 기준 열을 정한다.
- all은 공통된 값이 x, y 중 한쪽에 없을 때의 처리를 뜻한다. 기본값은 FALSE이다.
FALSE일 경우 공통된 데이터가 있을 때만 해당 행이 병합된다.
- all = TRUE 이면 x, y 중 어느 한쪽에 공통된 값을 가지는 행이 없을 때, 해당 쪽을 NA로 채워 병합한다.
결과적으로 x, y의 전체 행이 결과에 포함된다.
- all.x와 all.y를 사용하여 x, y 중 특정 쪽에 공통된 값이 없더라도 항상 결과에 포함되게 한다.

4. 그룹화하여 데이터 처리

species<-group_by(iris,Species)
summarise(species,total=sum(Sepal.Length))
- group_by라는 함수로 iris데이터에서 Species로 나눈 객체를 생성한다.
- 객체를 summarise 함수에 입력하여, 그룹화된 변수들에 따라 계산하게 한다.
- 계산값은 Sepal.Length열 값들의 합계가 되겠다.
다른방법 : iris%>%group_by(Species)%>%summarise(total=sum(Sepal.Length))
- %>%를 사용하여 위의 코딩을 더 짧게 요약해서 작성할 수 있다.
다른방법 : aggregate(Sepal.Length~Species,iris,sum)
- 기본 함수인 aggregate라는 함수를 사용하여도 가능하다.
* sqldf 패키지를 이용하여 R에서 sql언어로 데이터 처리하기
https://warm-uk.tistory.com/66?category=810499
[R, 전처리, 패키지] sqldf 패키지 이용하여 R에서 SQL을 사용하자
SQL에 익숙한 분들은, R에서 데이터 처리를 위하여 새로운 함수들을 쓰는 것 보다 sqldf 패키지를 사용하여 SQL를 R에서 사용하여 데이터 처리를 하는 것이 편할 것이다. 그럼 어떻게 해야 하는지 알
warm-uk.tistory.com
'데이터분석 > R' 카테고리의 다른 글
| [R, 시각화, 패키지] ggplot 패키지 사용하여 이쁘게 그래프 그리기2 - geom_bar(), 막대그래프 응용 (0) | 2021.06.28 |
|---|---|
| [R, 시각화, 패키지] ggplot 패키지 사용하여 이쁘게 그래프 그리기1 - geom_point(), geom_smooth() (0) | 2021.06.28 |
| [R, DB연동] ORACLE과 연동하여 R에서 SQL 사용하기 (0) | 2021.06.28 |
| [R, 시각화] 기본 그래프 그리기(파이, 히스토그램, 박스그래프, 화면분할) - pie(), hist(), boxplot() (0) | 2021.06.28 |
| [R, 시각화] 기본 그래프 그리기(막대 그래프) - barplot() (0) | 2021.06.28 |



