
욱이의 냉철한 공부
[NLP 개념정리] Word Embedding : Word2Vec 본문
* 자료출저 및 참고논문
- 강의
Coursera, Andrew Ng 교수님 인터넷 강의
- 논문
Word2Vec: 2013, Effcient Estimation of Word Representations in Vector Space
* Word Representation 관점 : Word Embedding 만들기
1. Discrete Representation : Local Representation
1) One - hot Vector
- One - hot Vector
2) Count Based
- Bag of Words (BoW)
- Document-Term Matrix (DTM)
- (TDM)
- Term Frequency-Inverse Document Frequency (TF - IDF)
- N-gram Language Model (N-gram)
2. Continuous Representation
1) Prediction Based (Distributed Representation)
- Neural Network Language Model (NNLM) or Neural Probabilistic Language Model (NPLM)
- Word2Vec
- FastText
- Embedding from Language Model (ELMo) (Bidirecional Language Model (biLM) 활용)
2) CountBased (Full Document)
- Latent Semantic Analysis (LSA)) <-DTM
3) Prediction Based and CountBased (Windows)
- GloVe
*
Discrete Representation은 값 그 자체를 표현, 정수로 표현된 이산표현
Continuous Representation은 관계, 속성의미를 내포하여 표현, 실수로 표현된 연속표현
목차 : Word2Vec
- Word2Vec 정의
- Word2Vec 종류
- Word2Vec 모델링 과정
- NPLM과 Word2Vec의 차이점
- Word2Vec 문제점 : 계산속도
1) Word2Vec 정의
Word(단어) 2(to) Vec(벡터)
즉 단어를 벡터로 바꾼다.
2) Word2Vec 종류
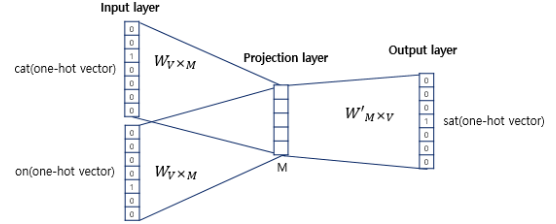
- CBOW(Continuous Bag of Words)
주변단어들을 확인하여 중심에 있는 Target을 예측
ex) The fat cat sat on the mat
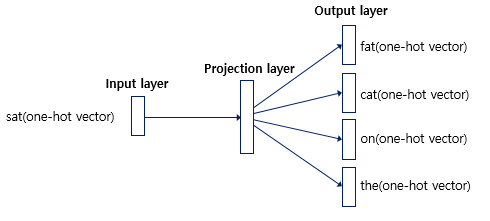
- Skip-Gram
중심에 있는 단어로 주변의 Target을 예측
ex) The fat cat sat on the mat
- Skip-Gram이 왜이름이 Skip(건너뛰다)-Gram(몇 칸)인가?
orange를 중심으로 가까히 있는 glass를 예측(학습)할 수도 있고, 멀리 있는my를 예측(학습)할 수도 있다.
만약 윈도우 크기 6을 사용한다면(-6~orange~+6) 크기 안에서 단어를 선택할 수 있다.
즉 orange+6의 위치에 있는 my를 학습범주 안으로 가져올 수 있는 것이다.
이처럼 몇 칸식 건너뛰어서 학습하기 때문에 Skip(건너뛰다)-Gram(몇 칸)이라고 명칭한다.
- Skip-Gram의 장점
CBOW보다 중심단어의 학습기회를 더 많이 가져가기 때문에, 학습량이 더 좋다고 할 수 있다.

3) Word2Vec 모델링 과정
ex) The fat cat sat on the mat


첫째 그림은 중심단어 sat으로 fat, cat, on, the 예측하지만,
나는 둘째 그림의 중심단어 orange를 예로 든다.
1. 입력층(Input layer)
- 차원 이해
x1: 10000 (원핫인코딩(단어수))
- 보충 설명
10000개 중에 1개만 1이고 나머지는 0인 원핫인코딩된 입력값.
2. 입력층(Input layer) -> 은닉층(Projection layer, Hidden layer)
- 차원 이해
가중치 매트릭스 (w1,b1): 10000 X 300 (원핫인코딩(단어수) X 노드수(관계피쳐))
- 내적 후 차원
z1 = x1 * w1 + b1 :(1 X 300)=(1 X 10000) X(10000 X 300)
- 보충설명
w1*x1의 내적과정에서 각 해당값을 참조한다고 하여, lookup이라고 말한다.
그리하여 나온 결과테이블인 z1을 lookup 테이블이라고 한다.

3. 은닉층(Projection layer, Hidden layer)
- 차원 이해
z1: 300
- 보충설명
첫째,여기서 사실 은닉층 하나만 있기 때문에 딥러닝이라 할 수 없다. 그냥 얕은신경망이다.
둘째,일반적인 Relu같은 활성화 함수가 따로 존재하지 않으며, 내적 결과값인Lookup 테이블만 존재한다.
4. 은닉층(Projection layer, Hidden layer) -> 출력층(Output layer)
- 차원 이해
가중치 매트릭스 (w2,b2):300 X 10000 (Lookup테이블(관계피쳐) X 노드수(단어수))
- 내적 후 차원
z2 = z1 * w2 + b2:(1 X 10000) =(1 X 300)X(300 X 10000)
- 보충설명
결국, 출력값 z2는 10000개로 이루어진 벡터값이며, 각 단어들을 의미한다.
5. 출력층(Output layer)
- 차원 이해
예측 Y= softmax(z2) : 10000
- 보충 설명
예측 Y 값은 최종 출력값이며 0과 1사이의 실수이고, 10000개의 각 원소의 총 합은 1이 된다.
이렇게 나온 최종 출력값, 벡터는 스코어 값이라고 명칭한다.
- softmax식
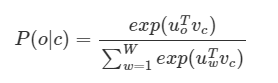
6) 학습 최적화 : 손실함수(loss function) 계산
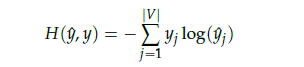
- L(예측값, 실제값)
이 손실함수를 줄이는 방향으로 역전파 실시
더불어최적의가중치 매트릭스(E)를 도출하는 방향으로 학습 진행
- 보충 설명
W1(가중치 매트릭스)과 W2(가중치 매트릭스) 두 개의 가중치 매트릭스가 학습되는데,
둘 중에 하나를 임베팅 벡터로 사용할 것을 결정하면 된다.
W1의 행 벡터(300차원, 관계피쳐)이나, W2의 열 벡터(300차원, 관계피쳐) 둘 중의 하나

4) NPLM과 Word2Vec의 차이점
1. 예측 대상 달라짐
NPLM은 언어모델을 통해 다음 단어를 예측,
Word2Vec은 워드임베딩 자체가 목적이므로 다음 단어가 아닌 중심단어를 예측하게 하여 학습에 집중
즉 전, 후 단어들을 모두 학습하면서 학습량 많아짐.
2. 모델링 구조.
Word2Vec은 활성화 함수를 사용하지 않고,
은닉층 하나인 얕은신경망이라고 할 수 있음.
3. Word2Vec의 효율성을 위한 기법들
Word2Vec은 학습 속도를 올릴 수 있는hierarchical softmax, negative sampling등의 기법을 활용함.
4. 연산량
NPLM :(n×m)+((n×m)×h)+(h×V)
Word2Vec : (n×m)+(m×v)
5) Word2Vec 문제점 : 계산속도
최종결과값 즉 확률도출을 위해분모에서 10000개의 단어를 계산하는 과정이 필요함.
10000개면 괜찮지만, 100,000 or 1,000,000개의 사이즈라면 , 계산하여분모를 합산하는 과정이 매우 느려짐.
하지만 이를 위한 해결책이 있다!!
=> 여러가지 해결책
1. hierarchical softmax
2. subsampling frequent words
3. negative sampling : 이것을 많이 사용함.

'데이터과학 > 개념 : NLP' 카테고리의 다른 글
| [NLP 개념정리] 이해하기 쉬운 분류체계 (0) | 2020.04.16 |
|---|---|
| [NLP 개념정리] Word Representation : 카운트 기반 단어표현 (0) | 2020.04.16 |
| [NLP 개념정리] Word Embedding : GloVe (0) | 2020.04.16 |
| [NLP 개념정리] Word Embedding : NNLM (1) | 2020.04.16 |
| [NLP 개념정리] Word Embedding 개요 (0) | 2020.04.16 |



