
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 빅데이터
- 그래프시각화
- 데이터시각화
- Deeplearning
- 머신러닝
- 데이터분석
- 자연어처리
- 딥러닝
- R그래프
- Hadoop
- lstm
- 주가예측
- word2vec
- SQL
- ggplot
- r
- 데이터처리
- Python
- CNN
- 하둡
- 그래프
- R시각화
- pandas
- 데이터
- HIVE
- R프로그래밍
- NLP
- 기계학습
- AI
- 빅데이터처리
- Today
- Total
욱이의 냉철한 공부
[데이터 크롤링] 개요 본문
* 목차
1. HTML
2. 인터넷 기본 용어
3. HTTP 요청방식 2가지 - GET, Post
4. HTML5
5. 개발자 도구
6. 크롤링
1. HTML
- HTML 역사
HTML은 1990년 CERN(유럽원자핵연구기구)에서 일하던 팀 버너스 리에 의해 개발
거의 동시에 HTTP와 URI, WWW와 같은 기본적인 구조와 세계 최초의 웹 브라우저도 개발
그 당시에는 HTML은 CERN 내의 연구 공유와 교환을 위해 사용
1993년 CERN이 WWW를 공개한 것과 인터넷 접속 서비스가 시작된 것을 계기로 표준 규격으로 자리잡게 됨
- HTML 버전의 역사
1993년 - HTML 1.0
1995년 - HTML 2.0
1997년 - HTML 3.0
1997년 - HTML 4.0
1999년 - HTML 4.01
2014년 - HTML 5
2. 인터넷 기본 용어
- URI(Uniform Resource Identifier)
'통합 자원 식별자'라고 하며, 인터넷상에서 존재하는 자원을 나타내기 위한 주소
- HTTP
WWW에서 정보를 주고 받을 때 사용하는 프로토콜,
클라이언트와 서버 간의 요청과 응답으로 정보를 전달
- HTML(Hyper Text Markup Language)
웹 문서를 만들기 위해서 사용하는 프로그래밍 언어의 한 종류
HTML 태그라는 특수 기호 사용하여 페이지를 작성
- Web Crawler
조직적, 자동화된 방법으로 WWW을 탐색하는 컴퓨터 프로그램
Crawler가 하는 작업을 web crawling 혹은 spidering이라 부른다.
3. HTTP 요청 방식 2가지 - GET, Post
1) GET 방식
URL에 변수를 포함시켜 요청
데이터가 헤더에 포함되어 전달
길이 제한이 있고, URL의 데이터가 노출
2) Post 방식
데이터가 본문에 포함되어 전달
URL에 데이터가 노출되지 않음
길이 제한이 없음
ex) 로그인 정보, 민감한 정보
4. HTML5
- 개요

- 태그목록
| 태그 |
기능 |
|
<a> |
하이퍼링크를 추가, href 속성을 사용하여 링크할 url을 지정. 메일 주소나 페이지 안의 다른 부분도 링크 가능 |
|
<h1> ~ <h6> |
문장의 제목을 생성, 숫자가 낮을수록 상위 레벨을 의미 |
|
<p> |
단란을 나타냄. 달리 표시할 요소가 없는 경우에 사용하기를 권장 |
|
<br> |
줄바꿈을 나타냄. 줄을 바꿀 문자의 끝에 <br>를 붙인다. 이 태그는 </br> 필요없음 |
|
<ul> |
번호가 없는 항목 쓰기의 범위를 나타냄. 항목은 <li>로 지정 |
|
<ol> |
번호가 붙은 항목 쓰기의 범위를 나타냄. 항목은 <li>로 지정 |
- <a> 태그

- <ul> 태그, <ol> 태그

- <p> 태그

- <div> 태그, <span> 태그
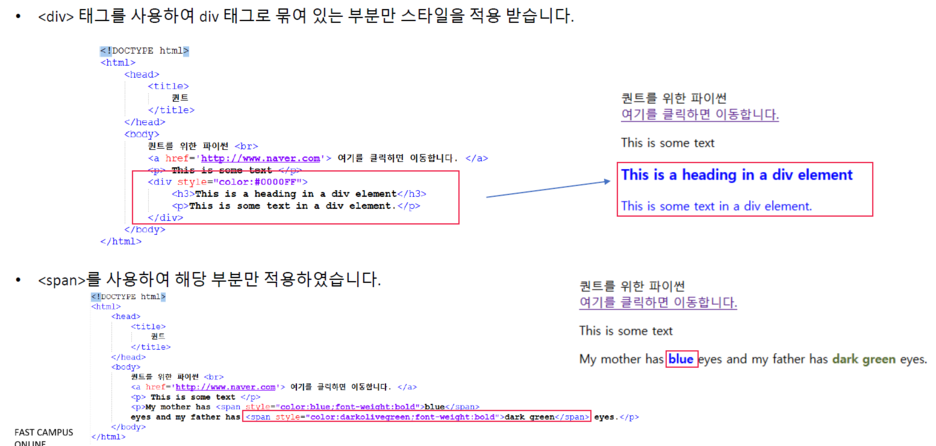
- <table> 태그

5. 개발자 도구
- 개발자 도구
크롬을 실행하여 키보드 F12키를 누르면 개발자 도구 나타남.
개발자 도구가 중요한 이유는 우리가 원하는 데이터가 html 안에서 어느 위치에 존재하는제 알려줌.
그러면 어떻게 알려주는가?
Elements 탭, network 탭을 통해서 알려줌.
- Elements 탭
1) 클릭한 부분의 html 태그 정보를 가지고 크롤링을 할 재료로 사용
=> tag, class, id 값을 찾고, 그 정보를 바탕으로 정보를 가져옴
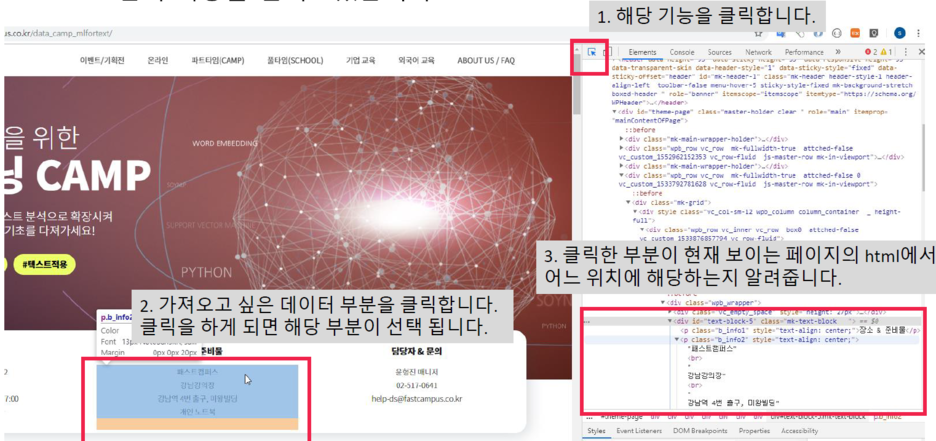
2) copy하여 크롤링에 활용

- network 탭
network탭의 기능은 내가 접속한 페이지와 현재 크롬하고는 통신을 하고 있는 중
페이지에서 로그인이나 혹은 페이지 안의 버튼을 클릭 한다는 것은 서버에게 이런 정보를 요청을 한다는 것.
그 정보를 다시 나에게 보내줘야 크롬에서 정상적으로 페이지가 출력됨.
network탭이 이 정보를 출력
=> 서버-클라이언트 간의 통신 내용을 알 수 있음

6. 크롤링
- 크롤러(crawler)
* 크롤러는 조직적, 자동화 된 방법으로 WWW를 탐색하는 컴퓨터 프로그램
크롤러가 하는 작업을 크롤링(crawling) 혹은 스파이더링(spidering)이라 한다.
쉽게 표현하면 웹 페이지에서 정보를 추출하기 위한 프로그램
크롤러는 스파이더(Spider) 혹은 봇(bot)이라고도 부름.
- 크롤링(crawling)
* 크롤링은 웹 페이지에서 데이터를 수집하여 다운로드 받는 작업을 의미
- 크롤링(crawling)을 파이썬으로 하는 이유
1) 웹 데이터 수집을 위한 라이브러리가 많고, 파이썬 언어의 간결성이 더해져서 다른 언어에 비해 코드 양 및 시간에 대한 이점
2) requests, selenium, beautifulSoup 등의 라이브러리를 사용해서 간단하게 구현
(다른 언어도 동일한 라이브러리 및 비슷한 라이브러리도 존재. 다만 파이썬이 다른 언어에 비해서 편하고 시간이 절약)
- 크롤링(crawling)의 방법
웹 페이지에서 데이터를 가져올 때 2가지를 고려
1) 우리가 원하는 데이터가 html안에 존재하는 경우
=> requests 라이브러리를 사용하여 단순하게 처리 가능.
하지만 requests의 단점으로는 자바스크립트로 코딩된 데이터는 가져올 수 없음
2) 데이터가 자바스크립트 및 ajax 기술을 사용하여 페이지가 구성된 경우
=> selenium이라는 라이브러리 힘을 빌려야 함.
더불어 Chrome, firefox, pantomJS 등의 프로그램의 도움이 함께 필요
* requests를 이용하여 데이터를 수집하는 것이 속도는 빠름
'데이터분석 > Python : Crawling' 카테고리의 다른 글
| [데이터 크롤링] 정규표현식 (0) | 2020.04.20 |
|---|---|
| [데이터 크롤링] requests, BeautifulSoup (0) | 2020.04.20 |
| [데이터 크롤링] OPEN API 네이버 검색 데이터 크롤링하기_실행하기 (0) | 2020.04.20 |
| [데이터 크롤링] OPEN API 네이버 검색 데이터 crawling 하기_이해하기 (0) | 2020.04.20 |



