
욱이의 냉철한 공부
[데이터 크롤링] 정규표현식 본문
* 목차
1. 정규표현식(Regular Expression)
2. 메타 문자
3. 수량자
4. re모듈
1. 정규표현식(Regular Expression)
- 정규표현식 개요
1) 정규표현식(Regular Expression) 또는 정규식(Regex)은 특정한 규칙을 가진 문자열 집합을 표현하는데
사용하는 언어. 많은 텍스트 편집기와 프로그래밍 언어에서 문자열의 검색과 치환을 위해 지원하고 있음.
2)특수한 문자열 패턴으로 데이터를 추출하는 일종의 도구
다른 도구들처럼 특정한 문제를 해결할 목적으로 만들어짐
=> 원하는 정보가 어디에 있는지검색하거나, 정보를 찾은 뒤에 해당 정보를 다른 정보로 치환할 때 사용
예시) 큰 범위의 텍스트에서 특정패턴과 일치하는 단어들을 검색하거나, 해당 패턴과 일치하는 문자열을 다른
문자열로 치환하는 방법을 적용할 수 있음. 즉 정규표현식은 문자열을 찾고 조작하는데 사용하는 문자열
- 정규표현식 사용 예시
1) 웹 페이지에서 숫자로 된 값들만 추출(검색)
2) 찾고 싶은 문자열이 소괄호안에 존재할 때, 소괄호 안의 문자들만 추출(검색)
3) 텍스트에서 대상 문자열 패턴을 특정한 문자로 치환하고 싶음.
* 정규표현식 연습 : https://regex101.com
2. 메타 문자
- 메타 문자
메타 문자는 특별한 의미를 가지고 있는 약속된 문자
예를 들어 정규 표현식에서 사용하는 .은 모든 글자를 의미
- 메타 문자 종류 : 횟수, 위치 및 그룹
dg로 시작해서 dooooog로 끝나는 텍스트 존재
ex) dg, dog, doog, dooog, doooog, dooooog, doooooog
|
메타 문자 |
설명 |
예제 |
|
* |
0회 이상을 반복 허용 (앞의 문자가 무한개로 존재할 수도 있고, 존재하지 않을 수도 있음) |
do*g -> dg, dog, doog, dooog, doooog, dooooog, doooooog |
|
+ |
1회 이상을 반복 허용 (앞의 문자가 최소 한 개 이상 존재) |
do+g -> dog, doog, dooog, doooog, dooooog, doooooog |
|
? |
0회 or 1회 반복만 허용 (앞의 문자가 존재할 수도 있고, 존재하지 않을 수도 있음) |
do?g -> dg, dog |
|
{m} |
m회 반복을 허용 (앞의 문자가 숫자만큼 반복) |
do{3}g -> dooog |
|
{m,n} |
m회부터 n회까지 반복을 허용 (?, *, +를 이것으로 대체할 수 있음) |
do{2,4}g -> doog, dooog, doooog |
|
. |
줄바꿈 문자를 제외한 모든 문자 (한 개의 임의의 문자를 나타냄) |
d.g -> dog 매칭 |
|
^ |
문자열의 시작과 매칭 (뒤의 문자로 문자열이 시작) * []안에서 사용되면 반대를 뜻함 ex)[^a]는 a가 아닌 문자 |
^dogs -> dogs and cats cats and dogs |
|
$ |
문자열의 마지막에 매칭 (앞의 문자로 문자열이 끝남) |
dogs$ -> dogs and cats cats and dogs |
|
[] |
문자 집합을 나타냄 [abc]의 의미는 a,b,c 중 문자를 의미 [a-c] 이렇게 -를 사용해서도 표현 가능 |
d[a-z]g -> dag, dbg, dcg, ddg .... dzg |
|
| |
a|b는 a or b 의 의미. |
d(a|o)g -> dag, dog |
|
() |
정규식을 그룹으로 묶음 |
|
- 메타 문자 종류 : 특수 문자
|
메타 문자 |
설명 |
|
\\ |
역슬래시 문자 자체를 의미한다 . |
|
\d |
모든 숫자와 매칭된다 . [0-9] 와 동일 |
|
\D |
숫자가 아닌 모든 문자와 매칭된다 . [^0-9] 와 동일 |
|
\s |
공백과 매칭 [ \t\n\r\f\v]와 의미가 동일 |
|
\S |
공백을 제외한 문자와 매칭 [^ \t\n\r\f\v]와 의미가 동일 |
|
\w |
숫자 또는 문자와 매칭된다 . [a-z0-9A-Z] |
|
\W |
숫자 또는 문자가 아닌 것과 매칭 [^a-z0-9A-Z] |
|
\b |
단어의 경계를 포현 단어는 영문자나 숫자의 연속 문자열로 가정 |
|
\B |
\b 와 반대로 단어의 경계가 아님을 표현 |
- 정규표현식 예시 : 메타 문자 적용
=> 이메일 정규표현식
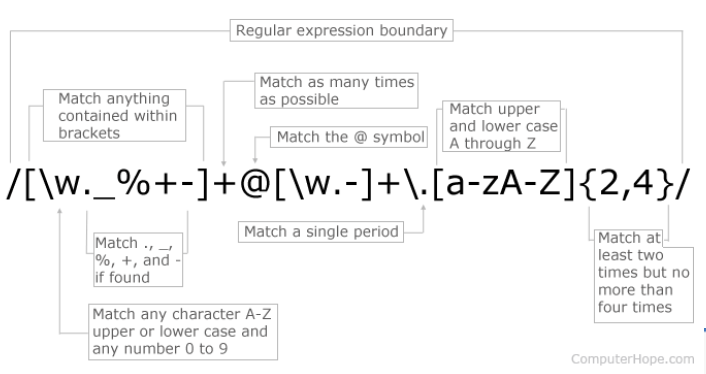
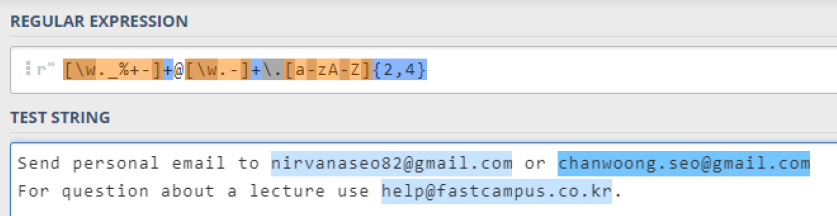
=> 이메일 정규표현식 검색하여 해당 STRING 추출
3. 수량자
- 수량자 개요
정규식은 처음부터 끝까지라는 생각을 가진 탐욕스러운 성질 지님. 이것을 Greedy Matching 이라 함.
매칭 특수 문자를 사용하여 덜 탐욕스러운 성질로 만들어 줄 수 있음. 이것을 Non-greedy Matching 이라 함
- 수량자 예시
횟수를 나타내는 정규표현식 뒤에 ?를 붙이면 문자열을 최소로 매칭해줌.
아래에서 위의 예시는 끝에 있는 "까지 처리하지만, 아래 예시는 가장 가까운 "까지만 처리, 즉 최소로 매칭

4. re 모듈
- re모듈 종류
강력한 기능을 가진 정규식을 파이썬에서는 표준 라이브러리 re모듈이 제공
|
모듈 함수 |
설명 |
|
re.compile() |
정규표현식을 컴파일하는 함수. 다시 말해, 파이썬에게 전해주는 역할을 합니다. 찾고자 하는 패턴이 빈번한 경우에는 미리 컴파일해놓고 사용하면 속도와 편의성면에서 유리 |
|
re.search() |
문자열 전체에 대해서 정규표현식과 매치되는지를 검색 |
|
re.match() |
문자열의 처음이 정규표현식과 매치되는지를 검색 |
|
re.split() |
정규 표현식을 기준으로 문자열을 분리하여 리스트로 리턴 |
|
re.findall() |
문자열에서 정규 표현식과 매치되는 모든 경우의 문자열을 찾아서 리스트로 리턴 만약, 매치되는 문자열이 없다면 빈 리스트가 리턴 |
|
re.finditer() |
문자열에서 정규 표현식과 매치되는 모든 경우의 문자열에 대한 이터레이터 객체를 리턴 |
|
re.sub() |
문자열에서 정규 표현식과 일치하는 부분에 대해서 다른 문자열로 대체 |
- search() 함수, match() 함수
match()함수는 문자열이 시작되는 곳부터 일치하는지 검사
search()함수는 부분적으로 일치하는 문자열이 있는지만 검사

- search() 함수 관련 활용 메소드
search() 함수를 사용하여 반환 된 search 객체에서
group()이나 groups() 메소드를 사용하면 정규식과 매칭된 문자열을 추출 가능.
|
메소드 |
내용 |
|
group() |
매칭된 전체 문자열을 반환 |
|
group(n) |
n번째 그룹 문자열을 반환 |
|
groups() |
매칭된 전체 그룹 문자열을 튜플형식으로 반환 |
|
start() |
문자열의 시작 위치 |
|
end() |
문자열의 끝 위치 |
|
span() |
(시작, 끝) 위치 튜플로 반환 |
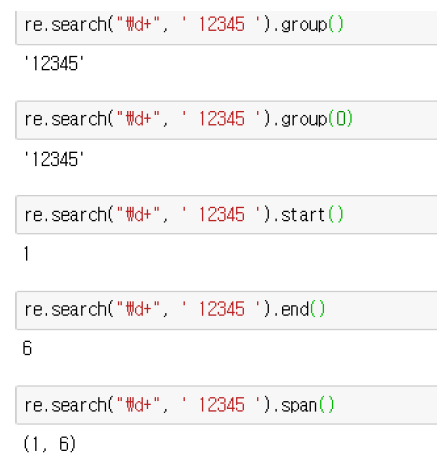
예시)
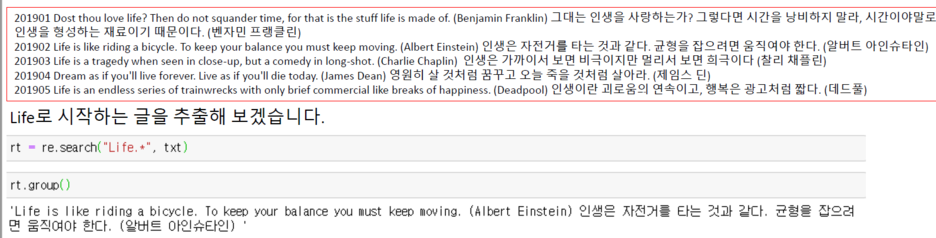
=> 문제) Life로 시작하는 명언이 하나만 존재하는 것이 아닌데, 출력은 하나만 출력됨.
해결) compile() 함수, findall() 함수 사용
- compile() 함수, findall() 함수
=> 문제
match(), search() 함수를 사용하면 사용할 때마다 정규식을 표현해야하고
전체 문장에서 둘 이상의 값을 찾을 수도 없음.
=> 해결
그리하여 compile() 함수 이용하여 정규식을 정규식 객체로 변환하고,
이 객체를 사용하여 findall() 함수를 통해 전체 문장에서 정규식 패턴에 부합되는 문자열을 모두 추출 가능


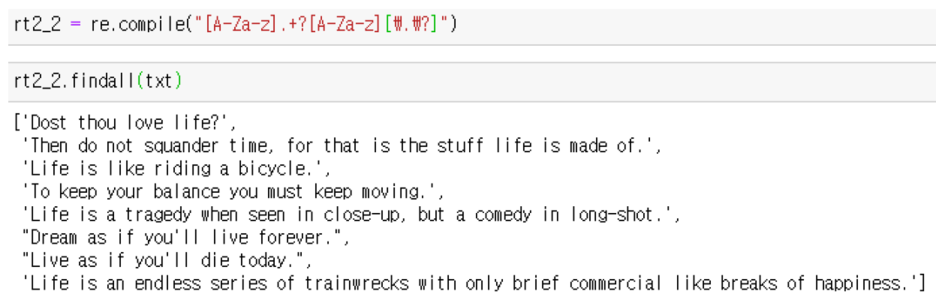
- compile() 함수, findall() 함수 : 예시) 예제에서 영어로 된 명언만 추출
1)
[A-Za-z] 알파벳 a~z, A~Z 로 시작되고 (모든 글자) + 하나 이상으로 있고 ,
[A-Za-z] 알파벳으로 끝나고 [\.] 마침표 또는 [\?] 물음표로 끝나는 모든 패턴을 추출


* 한글만 추출하고 싶다면 [A-Za-z] 대신 [가-힣]을 사용
2) 수량자 사용
- compile() 함수, findall() 함수 : 예시) 예제에서 저자들의 이름만 추출
후방탐색, 전방탐색을 사용하여 각각 '(', ')'를 함께 탐색한 후, 제외시킨후 이름만 추출

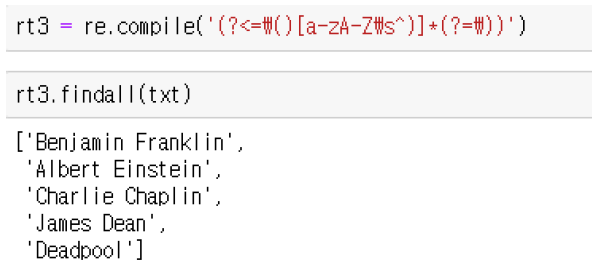
* 전방탐색, 후방탐색
?<= : 후방탐색 , ?= : 전방탐색
전방탐색, 후방탐색이 의미하는 것은 일치하는 부분을 제외하고 추출
전후방 탐색하여 () 안의 [a-zA-Z\s]( 모든 알파벳과 공백)이 0 번 이상 해당되는 값들이 출력
- sub() 함수 : 치환
sub() 메소드를 사용하면 찾은 값을 다른 값으로 변경
메소드 사용법 : sub(replacement, string[, count = 0])


- re 모듈의 정규식 플래그
정규식과 함께 사용하면서 더 좋은 효과 가져옴. compile(), search(), match() 함수의 인수로 사용.
|
플래그 |
설명 |
|
I, IGNORECASE |
대소문자를 구분하지 않고 매칭 |
|
L, LOCALE |
\w 와 \W, \b, \B 를 현재의 Locale 에 영향을 받는다 |
|
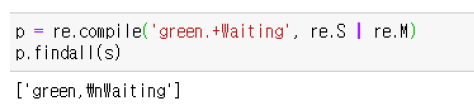
M, MULTILINE |
^가 문자열의 맨 처음, 각 줄의 맨 처음과 매칭 $는 문자열의 맨 끝, 각 줄의 끝에 매칭 이 플래그를 사용하지 않을 경우 ^는 문자열의 맨 처음만, $는 문자열의 맨 마지막만 매칭 |
|
S, DOTALL |
.을 개행 문자도 (\n)도 포함하여 매칭 해당 플래그를 사용하지 않으면 \n을 제외한 문자와 매칭 |
|
U, UNICODE |
\w, \W, \b, \B 가 유니코드 문자 특성에 의존하게 |
|
X, VERBOSE |
정규표현식을 보기 좋게 표현. 정규식 내 공백은 무시하며 공백을 사용할 때는 백슬래시 문자로 표현 정규식 내에서 # 문자를 사용하면 주석으로 이후의 모든 문자는 무시 |
- re 모듈의 정규식 플래그 예시
1) MULTILINE 플래그

2) DOTALL 플래그
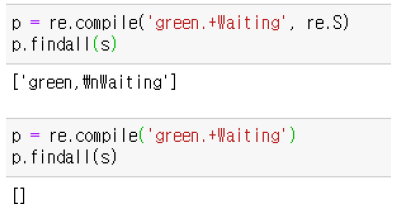
3) VERBOSE 플래그


4) 플래그 중첩
'데이터분석 > Python : Crawling' 카테고리의 다른 글
| [데이터 크롤링] requests, BeautifulSoup (0) | 2020.04.20 |
|---|---|
| [데이터 크롤링] 개요 (0) | 2020.04.20 |
| [데이터 크롤링] OPEN API 네이버 검색 데이터 크롤링하기_실행하기 (0) | 2020.04.20 |
| [데이터 크롤링] OPEN API 네이버 검색 데이터 crawling 하기_이해하기 (0) | 2020.04.20 |



