
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- NLP
- R그래프
- Python
- Hadoop
- 하둡
- 그래프
- 주가예측
- R시각화
- Deeplearning
- 딥러닝
- 데이터분석
- 머신러닝
- 빅데이터처리
- r
- CNN
- SQL
- 자연어처리
- AI
- ggplot
- 기계학습
- pandas
- word2vec
- lstm
- 빅데이터
- R프로그래밍
- 데이터시각화
- 데이터처리
- HIVE
- 데이터
- 그래프시각화
- Today
- Total
욱이의 냉철한 공부
[CNN 개념정리] CNN의 발전, 모델 요약정리 2 (ResNet, DenseNet) 본문
* 참고자료 및 강의
- cs231n 우리말 해석 강의
https://www.youtube.com/watch?v=y1dBz6QPxBc&list=PL1Kb3QTCLIVtyOuMgyVgT-OeW0PYXl3j5&index=6
- Coursera, Andrew Ng교수님 인터넷 강의
* 목차
1. 모델 발전 개요
2. 모델1 : LeNet-5
3. 모델2: AlexNet
4. 모델3 : ZFNet
5. 모델4 : VGG
6. 모델5 : GoogLeNet
7. 모델6 : ResNet
8. 모델7 : DenseNet
1. 모델 발전 개요
- 모델 목표
더 깊은 네트워크를 만들면서, 성능을 높여간다.
- 모델 목표를 위해 중요한 것.
HOW?
어떻게 학습능력을 높여서 더 깊은 네트워크를 학습했는가?
- 어떻게 학습능력을 높이는가?
1. LeNet-5 : CNN 적용하면서, 깊은 네트워크(4Layer) 학습하여 성능 상승
2. AlexNet : GPU, ReLU함수 사용하면서, 깊은 네트워크(8Layer) 학습하여 성능 상승
3. ZFNet : 하이퍼파라미터 최적화하면서, 깊은 네트워크(8Layer) 학습하여 성능 상승
4. VGGNet : 작은 필터 수(3x3) 규칙적으로 적용하면서, 깊은 네트워크(19Layer) 학습하여 성능 상승
5. GoogleNet : Inception 모듈 적용하여 효율성 높이면서, 더 깊고 넓은 네트워크(22Layer) 학습하여 성능 상승
6. ResNet : Skip connection적용하여 기울기소실문제 해결하면서, 매우 깊은 네트워크(152Layer) 학습하여 성능 상승
7. DenseNet : 진화된 Skip connection과 bottleneck layers를 적용하면서, 알짜배기 Feature만 가진 매우 깊은 네트워크를 학습하여 성능 상승

2. 모델6 : ResNet
- 동기 (기존의 문제)
네트워크가 깊어지면서, 학습은 어렵
1) 원인 1 : 학습 자체가 어렵
파라미터 수가 늘어나 생기는 Overfitting 문제가 아니여도, 학습성능 자체의 에러가 크다.
2) 원인 2 : 기울기소실문제
이 문제를 해결하고자, batch normalization 등을 적용했지만 네트워크 깊이를 더 늘리는데 있어 한계

- 핵심 아이디어 : Skip connection
Skip connection이라는 아이디어 적용
Skip connection은 입력에서 바로 출력으로 연결되는 것
기존 네트워크 : H(x)를 얻기 위해 학습. (출력 : H(x))
Resnet 네트워크 : 기존의 출력값(H(x))에서 입력값(x)을 뺀 차이를 얻기 위해 학습. (출력 : H(x) = F(x) + x)
* Resnet 네트워크의 목표
F(x)가 0이 되게 하는 것.
이렇게 되면 입력의 작은 움직임도 쉽게 검출.
즉 나머지(작은 움직임)을 학습시킬 수 있다는 의미에 residual learning이라는 이름 정의
=> 이와 함께 적어도 X는 학습하기 때문에 손해는 잃어나지 않는다.


1) 원인1을 해결하는 효과 : 깊은 네트워크 학습 가능
입력과 같은 x가 그대로 출력에 연결이 되기 때문에 파라미터 수의 영향이 없음.
또한 덧셈이기 때문에 skip connection(short-cut connection)에 의한 연산량 증가도 없음.
더불어 몇 개의 layer 계속 건너 뛰면서 입력과 출력이 연결되기 때문에 forward, backward path 단순.
2) 원인 2를 해결하는 효과 : 기울기소실 해결
기존 네트워크 : 역전파로 가중치를 업데이트 할 때, 앞 층으로 갈수록 기울기가 0으로 소실
resnet 네트워크 : f(X)에 추가된 +X 덕분에, 역전파 시 앞 층에 기울기 1 이 추가
ex)
Skip connection으로 gradient는 dhf(x)/dx = 1이 됩니다.
그리하여 previous layer에 최종 전달 되는 gradient는 [0.0001, 0.01]에서 [1, 0.0001, 0.01]이 됩니다.
1이라는 gradient가 더 추가가 되어서 Previous layer에 전달이 됩니다. 이런 이론을 적용하면 gradient vanishing을 줄일 수 있음.

- 모델 설명

2. 모델7 : DenseNet
- 동기 (기존의 문제)
"기울기소실문제해결"과 "feature 추출" 관점에서 더 발전시키자.
* 발전 목표
진화된 Skip connection과 bottleneck layers를 적용하면서, 알짜배기 Feature만 가진 매우 깊은 네트워크를 학습하여 성능 상승
=> 이를 통해 얻어지는 효과
1. They alleviate the vanishing-gradient problem
2. Strengthen feature propagation
3. Encourage feature reuse
4. Substantially reduce the number of parameters
- 핵심 아이디어
1) Resnet의 Skip-connection에서 발전된 Dense-connection
* Resnet 네트워크 : Skip-connection

* Densenet 네트워크 특징 : Dense-connectivity
1. 정보 보존
DenseNet은 네트워크에 추가 된 정보와 보존 된 정보를 명시적으로 구분한다.
DenseNet의 layer는 very narrow(e.g. 12 filters per layer)하며 네트워크의 “collective knowledge”에 적은 수의 feature-map set만 추가하고, 나머지 feature-map은 변경하지 않는다. 또한, 최종 classifier는 네트워크의 모든 feature-map에 기반하여 결정한다.
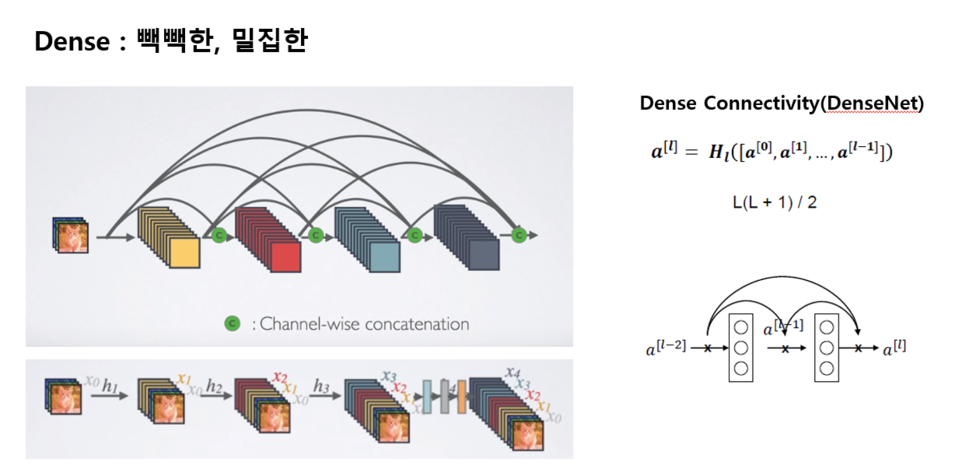
2. 일정하게 늘어나는 Connection 개수
등차수열 비율로 빽빽해진(Dense) 네트워크 구조 : 여기서 네트워크 이름 정의
기존의 L이 아니라 등차수열 공식에 따라 일정하게 늘어나는 conection 개수
ex) 기존의 3번째 Layer는 3개의 Connection이 있었다. 하지만 Densenet에서는 3번째 Layer에서 L(L+1)/2 공식에 따라 6개의 Connection이 생긴다.
3. Resnet의 F(x) + x 에서는 sum을 사용, 하지만 Densenet에서는 concatenation 사용
4. 모든 Layer가 동일한 feature-map 크기 사용 : 네트워크의 Layer간 information flow를 극대화
* 이를 통해 얻어지는 Densenet 네트워크의 효과
1. They alleviate the vanishing-gradient problem
각 layer는 loss function과 original input signal로부터의 gradient에 직접 액세스 할 수 있으므로, 유사 deep supervision이 이루어진다.
이는 deeper network architecture의 학습에 도움된다.
2. Strengthen feature propagation
1. 모든 Layer가 동일한 feature-map size : 네트워크의 Layer간 information flow를 극대화
2. 정보보존 : Feed-forward 특성을 유지하기 위해, 각 layer는 모든 선행 layer로부터 additional input을 취하며, 각 feature-map은 모든 후속 layer로 전달된다.
3. Encourage feature reuse
DenseNet은 extremly deep 하거나 wide한 구조로부터 representational power를 끌어내는 대신,
feature의 재사용을 통해 네트워크의 잠재력을 활용함으로써, 학습하기 쉬우면서도 효율적인 parameter를 가진 압축 모델을 만든다.
2) Densenet에 Bottleneck layers를 적용
* Bottlenck layers를 적용하지 않은 Densenet
여기서 hyperparameter k(동일한 필터수)를 네트워크의 growth rate라고 한다.
이 hyperparameter k(동일한 필터수)를 각 layer마다 계속 적용하여 feature-map을 출력
더불어 layer마다 모든 이전 feature-map에 새로운 feature-map을 계속 concatenation 함.
즉 각 layer들이 block 내의 모든 이전 feature-map에 접근함에 따라, 네트워크의 “collective knowledge”에 액세스 된다는 것이다.
Feature-map을 네트워크의 global state로 볼 수 있으며, 각 layer는 각자의 k feature-map에 이 state를 추가한다.

* Bottlenck layers

* Bottleneck layers와 Transition Layer를 적용한 Densenet
1. Bottleneck
2. Transition Layer
모델을 보다 작게 만들기 위해, transition layer에서 feature-map의 개수를 줄일 수 있다.
Dense block이 m개의 feature-map을 포함하는 경우, 뒤따르는 transition layer에서 출력 feature-map을 θm개 생성한다.
여기서 θ는 compression factor라고 한다.
θ는 0 < θ <=1 범위이다.
θ=1인 경우, transition layer의 feature-map 개수는 변경되지 않는다.

* 이를 통해 얻어지는 Densenet 네트워크의 효과
4. Substantially reduce the number of parameters
- 전체 모델 설명
1. Dense Blcok
2. Transition Layer
다운샘플링 : feature map의 가로, 세로 사이즈를 줄여주고 feature map의 개수를 줄여주는 역할을 담당하고 있습니다.
3. Classification Layer
fully connected layer를 사용하지 않으면서 파라미터 수 감소

'데이터과학 > 개념 : CNN(OD), RNN' 카테고리의 다른 글
| [RNN 개념정리] RNN/LSTM 기본개념 (4) | 2020.06.22 |
|---|---|
| [CNN 개념정리] CNN 기본개념 (0) | 2020.05.01 |
| [CNN 개념정리] CNN의 발전, 모델 요약정리 1 (AlexNet ~ GoogLeNet) (1) | 2020.04.21 |


