
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데이터처리
- R프로그래밍
- 데이터분석
- r
- 데이터시각화
- SQL
- word2vec
- 빅데이터처리
- CNN
- HIVE
- 그래프시각화
- 하둡
- 주가예측
- 그래프
- R그래프
- 빅데이터
- 데이터
- 자연어처리
- NLP
- pandas
- 딥러닝
- R시각화
- lstm
- 기계학습
- ggplot
- 머신러닝
- Hadoop
- Python
- AI
- Deeplearning
- Today
- Total
욱이의 냉철한 공부
[Hadoop, Hive] 빅데이터 Hive로 MapReduce 본문
SQL과 비슷한 HQL언어를 사용하여 Hive로 빅데이터를 MapReduce 하는 방법을 알아보자.

1. start-all.sh
합체 시스템 hive를 실행하기 전에 먼저 hadoop을 실행한다.
2. jps
hadoop 실행 환경을 확인한다.
3. ls $HIVE_HOME/examples/files
운영체제 HIVE 폴더에서 이후에 HIVE로 가져올 데이터 파일들을 확인한다.
그리고 hive를 입력하여 hive에 접속한다.
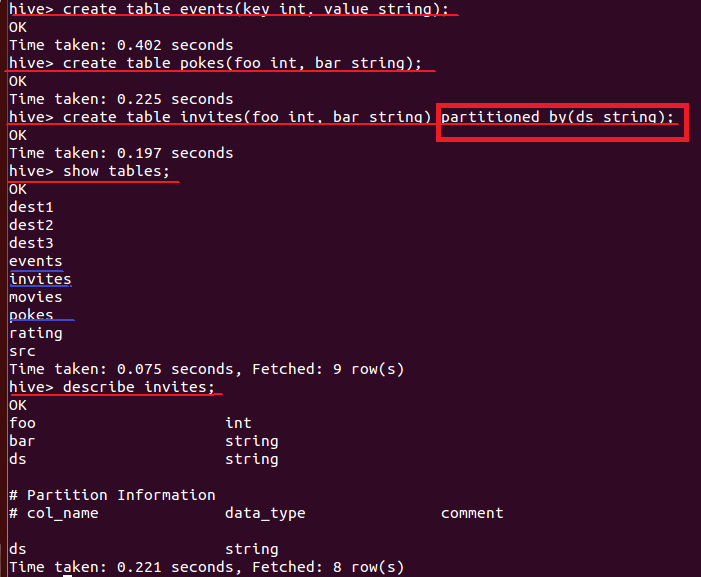
4. create table events(key int, value string);
- sql과 비슷한 hive의 hql언어를 지금부터 사용한다.
- events라는 table을 만든다.
- 이 테이블에 운영체제에 있는 우리가 필요한 파일을 넣을 것이다.
5. create table pokes(foo int, bar string);
- pokes라는 table을 만든다.
6. create table invites(foo int, bar string) partitioned by(ds string);
- invites라는 테이블을 만든다.
- partition 사용,
일반 테이블과 다르다.
데이터 집어 넣을 때 partition으로 구별한다. 날짜로 많이 활용한다.
7. show tables;
- 현재 어떤 테이블들이 있는지 확인한다.
8. describe invites;
- invites 테이블의 구조를 확인한다.

9. alter table pokes add columns(new_col int);
- pokes 테이블에 new_col이라는 열을 추가한다.
10. load data local inpath '/home/user1/hive-install/apache-hive-1.2.1-bin/examples/files/kv1.txt' overwrite into pokes;
- 운영체제 /home/user1/hive-install/apache-hive-1.2.1-bin/examples/files/kv1.txt 의 경로에 있는 kv1.txt 데이터를 hive의 pokes 테이블에 집어넣는다.
- load data local inpath에서 local은 운영체제를 뜻한다.

11. select * from pokes limit10;
- 데이터가 투입된 pokes 테이블을 hive에서 출력해본다.

12. load data local inpath '/home/user1/hive-install/apache-hive-1.2.1-bin/examples/files/kv2.txt' overwrite into table invites partition(ds='2008-08-15');
- 위 과정과 똑같은 방법으로 invites테이블에 운영체제에 있는 kv2.txt의 데이터를 집어넣는다.
- partition테이블이기 때문에 2008-08-15이라고 표시를 한다.
13. load data local inpath '/home/user1/hive-install/apache-hive-1.2.1-bin/examples/files/kv3.txt' overwrite into table invites partition(ds='2008-08-08');
- 위 과정과 똑같은 방법으로 invites테이블에 운영체제에 있는 kv3.txt의 데이터를 집어넣는다.
- kv2.txt와 다르다는 것을 구별하기 위해 partition을 표시한다. 2008-08-08이라고 표시한다.

14. select * from invites limit 20;
- partition 테이블 invites를 출력해본다.

15. select count(*) from invites;
- invites의 총 행 수를 집계한다.
- 계산이 들어가는 지금부터 하둡의 MapReduce 작업을 실행한다.
- select는 MapReduce이다.

16. insert overwrite directory 'output/' select bar, avg(foo) from invites where ds='2008-08-15' group by bar;
- 파랑색 직사각형을 통해 MapReduce 작업을 실행하는 것을 알 수 있다.
- 결과치를 Hadoop HDFS 시스템에 저장한다.
- 결과치는 select bar, avg(foo) from invites where ds='2008-08-15' group by bar
즉 2008-08-15인 데이터중에 bar로 그룹을 나누고 그 그룹의 평균 foo 값이다.
- Hadoop의 output/ 경로에 HDFS파일로 저장한다.
17. insert overwrite local directory '/tmp/local_out' select bar, avg(foo) from invites where ds='2008-08-08' group by bar;
- 파랑색 직사각형을 통해 MapReduce 작업을 실행하는 것을 알 수 있다.
- 결과치를 운영체제에 저장한다.
- 결과치는 select bar, avg(foo) from invites where ds='2008-08-08' group by bar
즉 2008-08-08인 데이터중에 bar로 그룹을 나누고 그 그룹의 평균 foo 값이다.
- 운영체제의 /tmp/local_out 경로에 저장한다.

18. exit로 hive를 종료한다.
19. hadoop fs -tail output/000000_0
- tail 하둡 명령어 사용
- 16번 과정에서 HDFS시스템에 저장한 결과치인 HDFS파일 000000_0을 일부분 확인한다.
- hive에서 저장초기이름명은 000000_0이다.
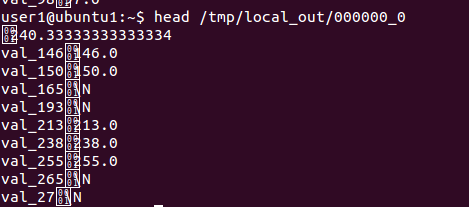
20. head /tmp/local_out/000000_0
- head는 운영체제 명령어
- 17번 과정에서 운영체제에 저장한 결과치인 000000_0을 일부분 확인한다.
- hive에서 저장초기이름명은 000000_0이다.
'데이터엔지니어링 > 빅데이터 : Hadoop' 카테고리의 다른 글
| [Hadoop, Pig] 빅데이터 Pig 이해하기 (0) | 2021.06.22 |
|---|---|
| [Hadoop, 하둡] 빅데이터 MAPREDUCE로 WordCount2 - R시각화 (0) | 2021.06.22 |
| [Hadoop, Hive] 빅데이터 Hive 이해하기 (0) | 2021.06.22 |
| [Hadoop, 하둡] 빅데이터 MAPREDUCE로 WordCount (0) | 2021.06.22 |
| [Hadoop, 하둡] 빅데이터 하둡 이해하기 (1) | 2021.06.22 |



