
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 데이터시각화
- Hadoop
- 데이터
- 빅데이터처리
- word2vec
- 딥러닝
- 그래프시각화
- 기계학습
- SQL
- R그래프
- CNN
- r
- Python
- 데이터분석
- 주가예측
- pandas
- NLP
- 데이터처리
- 머신러닝
- 자연어처리
- lstm
- 빅데이터
- 그래프
- ggplot
- R시각화
- R프로그래밍
- Deeplearning
- AI
- HIVE
- 하둡
- Today
- Total
욱이의 냉철한 공부
[Hadoop, 하둡] 빅데이터 MAPREDUCE로 WordCount2 - R시각화 본문
하둡 대표 명령어 - OS명렁어(unix명령어)하고 비슷한 shell 명령어
- hadoop fs -help : 하둡 fs에서 제공하는 명령어 확인
- hadoop fs -ls : 지정된 폴더나 파일 정보를 출력, 권한정보, 소유자, 생성일자, 바이트 수 확인
- hadoop fs -lsr : 현재 폴더 및 하위 디렉토리 정보까지 출력
- hadoop fs -du : 지정된 폴더나 파일에 사용량을 확인하는 명령어
- hadoop fs -dus : du는 폴더와 파일별 용량 / dus는 전체 합계 용량
- hadoop fs cat : 지정된 파일의 내용을 출력. 텍스트 파일만 출력
- hadoop fs -mkdir : 지정된 경로에 폴더를 생성, 이미 존재하면 error
- hadoop fs -put [운영체제폴더파일][HDFS] : 지정된 운영체제 폴더나 파일을 HDFS에 복사
- hadoop fs -get [HDFS][운영체제폴더파일] : HDFS에 저장된 파일이나 폴더를 OS로 이동
- hadoop fs -rmr : 지정한 파일이나 폴더를 삭제
- hadoop fs -sts : 지정된 경로의 통계 정보 출력
- hadoop fs -expunge : 휴지통비우기, HDFS는 삭제한 파일을 일정기간동안 보관함
=> 하둡명령어와 자바패키지와 함께 MAPREDUCE(wordcount)를 실행해보고 TOP20을 선별한 후 R과 연계하여 시각화까지 해볼께요!
=> WordCount 결과는 아래 포스팅으로 확인 할 수 있습니다.
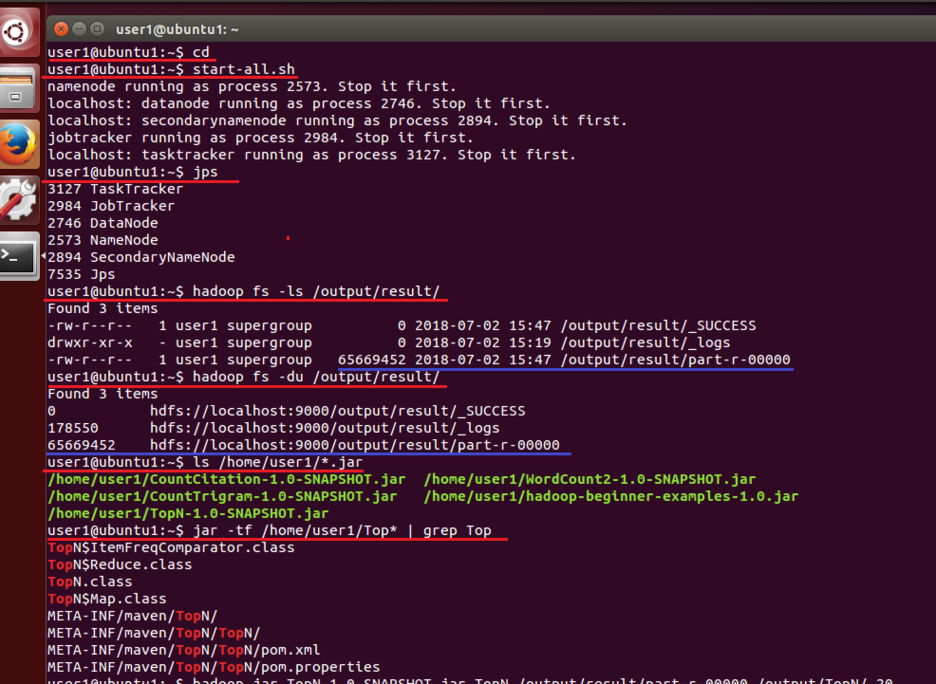
1. start-all.sh
- 하둡세상으로 접속한다.
- 앞으로 하둡프로그램에 접속하였을 때 하둡세상이라고 지칭하겠다.
2. jps
- 하둡세상을 가동하기 위한 환경이 잘 설정되어있는지 확인한다.
3. hadoop fs -ls /output/result/
- 하둡세상의 홈에서 /output/result 경로에 어떤 폴더들과 파일들이 있는지 확인한다.
- 앞서 wordcout한 part-r-00000이 있다는 것을 확인 할 수 있다.
4. hadoop fs -du /output/result/
- 하둡세상의 홈에서 /output/result 경로의 폴더들과 파일들의 사용량을 확인한다.
5. ls /home/user1/*jar
- 미리 자바패키지를 운영체제의 홈에 이동해 놨다.
- /home/user1(운영체제의 홈 경로)에 jar 파일들이 있는지 확인한다.
- 사용하기 위한 TopN이 있다는 것을 확인 할 수 있다.
6. jar -tf /home/user1/Top* | grep Top
- jar –tf 는 자바 명령어으로써 자바 프로그램 찾아준다.
- TopN파일 내에 Top 관련 클래스들이 있다는 것을 확인 할 수 있다.

7. hadoop jar TopN-1.0-SNAPSHOT.jar TopN /output/result/part-r-00000 /output/result2/ 20
TopN-1.0-SNAPSHOT.jar
: 운영체제의 홈 경로에 TopN-1.0-SNAPSHOT.jar라는 자바패키지가 있다.
TopN : 이 자바패키지에서 TopN라는 기능을 실행시킨다.
/output/result/part-r-00000 : 하둡세상의 result폴더의 part-r-00000파일을 대상으로 TopN 기능을 실행한다.
/output/result2 : 실행 결과를 하둡세상에 있는 output/result2 폴더에 저장한다.
20 : 위에서부터 20개만 추출한다.
=> 자바로 이루어진 코딩을 직접 입력할 필요 없이 만들어진 자바 패키지를 실행한다.
=> 파랑색 박스를 통해서 MapReduce 작업이 실행되고 있다는 것을 확인 할 수 있다.

8. hadoop fs -lsr /output/result2
- 하둡세상에 있는 output/reuslt2 폴더 내부에 있는 파일 및 폴더를 확인한다.
- part-r-00000로 Reduce 되어 있는 HDFS파일이 있는 것을 확인할 수 있다.
9. hadoop fs -cat /output/result2/part-r-00000
- 지정된 part-r-00000 파일을 출력할 수 있다.(텍스트 파일만 출력)
- 20개가 출력되는 것을 확인할 수 있다.
10. hadoop fs -get /output/result/part-r-00000 $HOME/new1.txt
- 하둡세상에 있는 HDFS파일인 part-r-00000을 운영체제의 홈에 new1.txt명으로 복제시킨다.
11. head $HOME/new1.txt
- 운영체제의 홈에 있는 new1.txt파일의 앞부분은 출력한다.
- R로 시각화 하기
12. R
- R을 미리 설치했다면 R을 입력함으로써 R에 접속합니다.
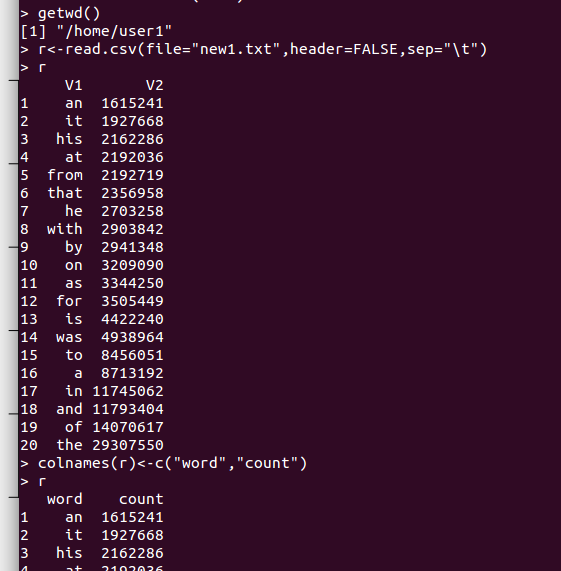
13. getwd()
- R의 기본 홈 설정이 운영체제 홈으로 설정되어 있다는 것을 알 수 있습니다.
14. r<-read.csv(file="new1.txt",header=FALSE, sep="\t")
- 운영체제 홈에 있는 wordcount, topN 의 MapReduce를 실행한 결과 new1.txt 파일을 R세상으로 불러옵니다.
15. colnames(r)<-c("word","count")
- 불러온 데이터프레임 r의 열이름을 word와 count로 변경합니다.

16. b<-barplot(r$count,names.arg=r$word,main="count of word",xlab="word",ylab="count",cex.names=1.3,col="lightcyan",las=2)
- 막대그래프로 표현하기 위해 barplot을 사용합니다.
- 데이터 프레임에서 x축을 표현하기 위해서는 names.arg를 사용합니다.
- main은 제목명이고 xlab은 x축 이름, ylab은 y축 이름입니다.
- cex.names는 x축의 변수명들의 크기를 나타냅니다.
- col는 막대그래프의 색깔입니다.
- las는 x축의 변수명들의 방향입니다.
17. text(x=b,y=r$count*0.9,labels = r$count,col="black",cex=1.0)
- 막대그래프 위에 count 수치를 표현하기 위해 text를 사용합니다.
- x, y는 좌표값을 뜻합니다.
- labels는 표현하기 위한 값을 나타냅니다.
- col는 값의 색깔입니다.
- cex는 값의 크기입니다.

- 문서 빅데이터를 wordcount하고 가장 많이 나온 단어 20개를 추려 시각화를 한 결과입니다.
- the라는 단어가 가장 많이 사용되었다는 것을 알 수 있습니다.
- 저장하기 위해서는 savePlot("count of word",type="png")를 입력하면 됩니다.
- 종료하기 위해서는 q() 입력하면 R세상을 종료합니다.
'데이터엔지니어링 > 빅데이터 : Hadoop' 카테고리의 다른 글
| [Hadoop, Pig] 빅데이터 Pig로 만져보기 - R시각화 (0) | 2021.06.22 |
|---|---|
| [Hadoop, Pig] 빅데이터 Pig 이해하기 (0) | 2021.06.22 |
| [Hadoop, Hive] 빅데이터 Hive로 MapReduce (0) | 2021.06.22 |
| [Hadoop, Hive] 빅데이터 Hive 이해하기 (0) | 2021.06.22 |
| [Hadoop, 하둡] 빅데이터 MAPREDUCE로 WordCount (0) | 2021.06.22 |



