
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 빅데이터처리
- ggplot
- Hadoop
- NLP
- 주가예측
- Deeplearning
- word2vec
- r
- pandas
- 데이터시각화
- 데이터분석
- 그래프시각화
- R프로그래밍
- Python
- CNN
- 하둡
- lstm
- 머신러닝
- 데이터처리
- R그래프
- SQL
- 데이터
- 기계학습
- 자연어처리
- 딥러닝
- 빅데이터
- 그래프
- AI
- R시각화
- HIVE
- Today
- Total
욱이의 냉철한 공부
[딥러닝 기본] Hyperparameter tuning : 하이퍼파라미터 튜닝 본문
* 출저
본 개념정리는 제 지도교수님이신 연세대학교 정보대학원 김하영 교수님 수업과 Andrew 교수님의 Coursera 수업을 통해 얻은 정보를 통해 정리했습니다. 자료는 대부분 Andrew 교수님의 Coursera 수업자료입니다.


1. Tuning process
1) 일반적인 우선순위
1. a(학습률)
2. b(모멘텀 값), hidden units(은닉층 유닛수), mini-batch size(미니배치 크기)
* Adam 최적화 알고리즘 사용시 : b1[0.9], b2[0.99], 앱실론[10-8] 초기화
3. layers(층 개수), learning rate decay(학습속도감쇠법) 등

2) Hyperparameters 서칭 방법
1. 그리드서치
그리드서치는 매개변수 적을 때 유용하다.
중요한 파라미터를 다양하게 서칭하기 어렵다.
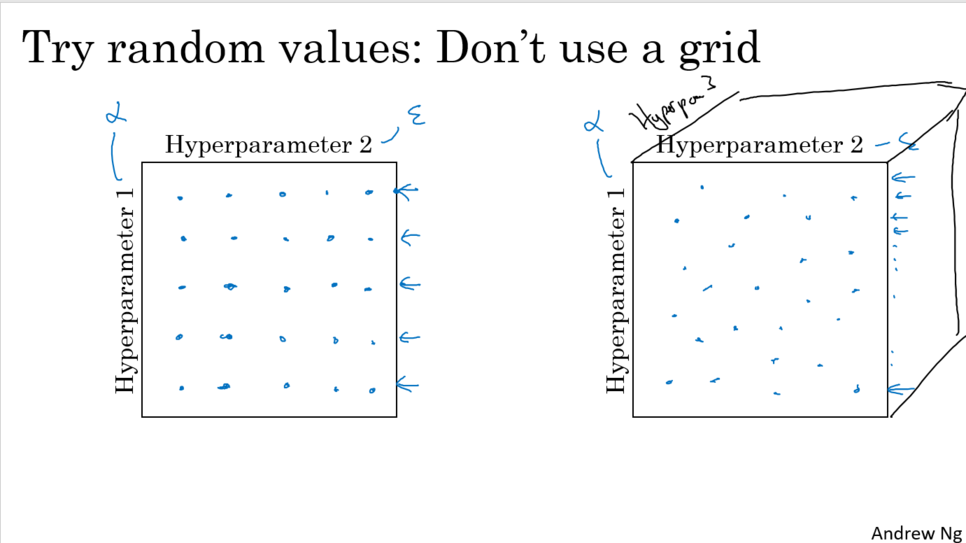
2. 랜덤서치
랜덤서치가 딥러닝에서는 더 유용하다.
왜냐하면 중요도가 다른 하이퍼파라미터의 최적의 값 후보가 다양하기 때문이다.
랜덤서치는 이러한 후보 값들을 광범위하게 서칭 할 수 있다.
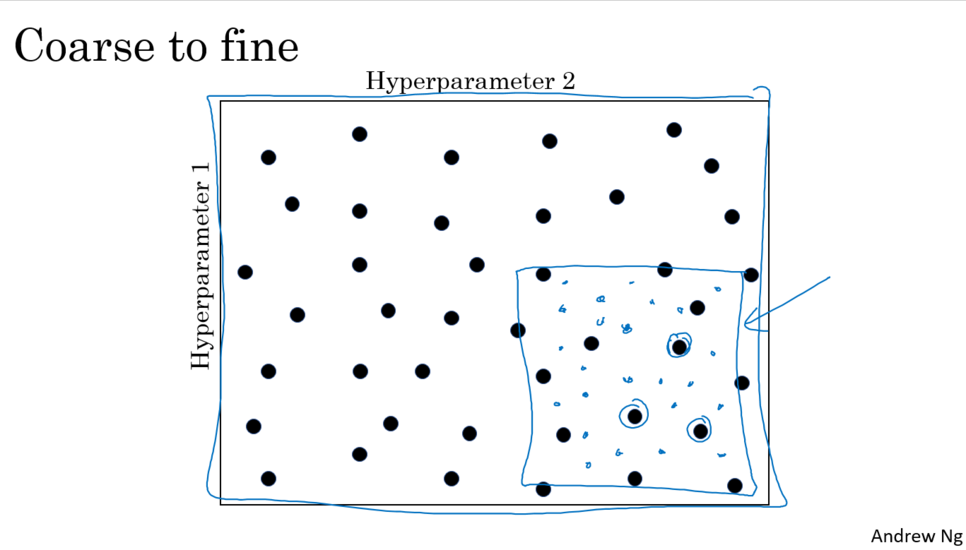
3. Coarse to fine
최적의 값 후보 서칭 범위를 더 확대해서 찾는 방법이다.
2. Using an appropriate scale to pick hyperparameters
- Picking hyperparameters at random
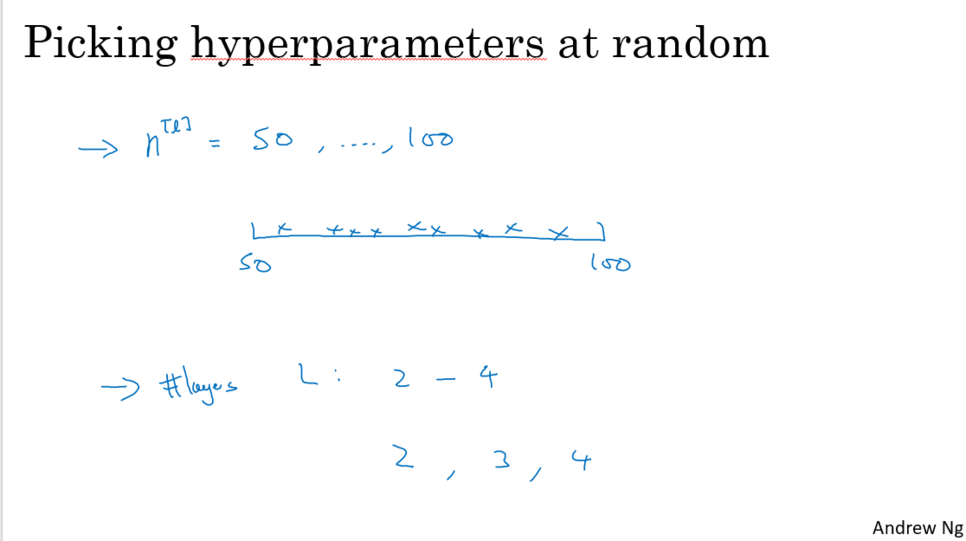
- Appropriate scale for hyperparameters
1. 예시 : a (학습률)
균일한 방법으로 샘플링 할 경우 0.1~1에 90%가 집중된다.
하지만 많이 쓰이는 a값은 0.1 근처에 많이 있다.
그렇기 때문에 로그스케일을 이용한다.
-> 0.0001 – 0.001 – 0.01 – 0.1 – 1 사이는 균일해진다.
2. 예시 : b (모멘텀 매개변수)
b는 1로 갈수록 변경사항 민감해진다. (보통 0.9가 적정 초기값)
많은 이전 값들이 관여되어지기 때문에 변경사항이 많아진다.
즉 1로 갈수록 많이 사용되어야 하는 값들이 많다.
그렇기 때문에 로그스케일을 이용한다.
-> 0.9 – 0.99 – 0.999 사이는 균일해진다.

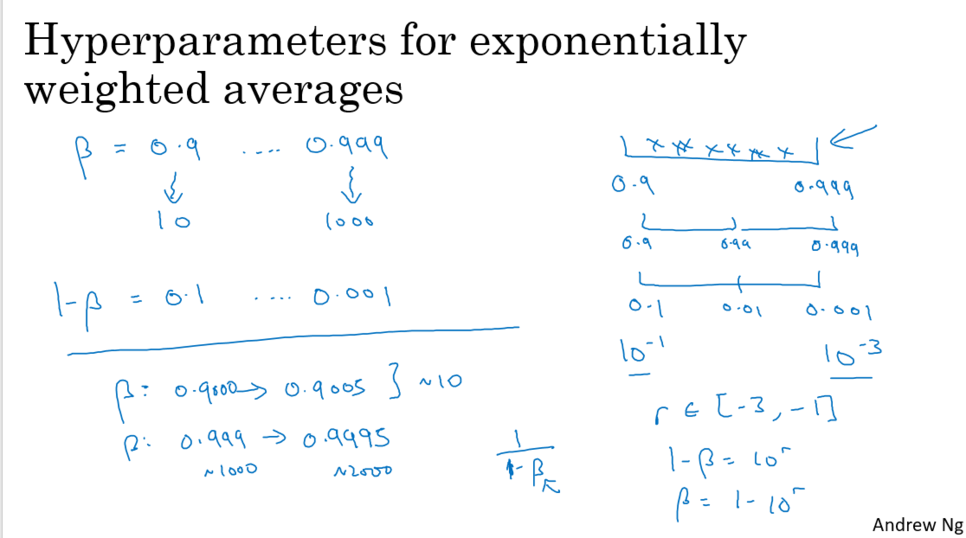
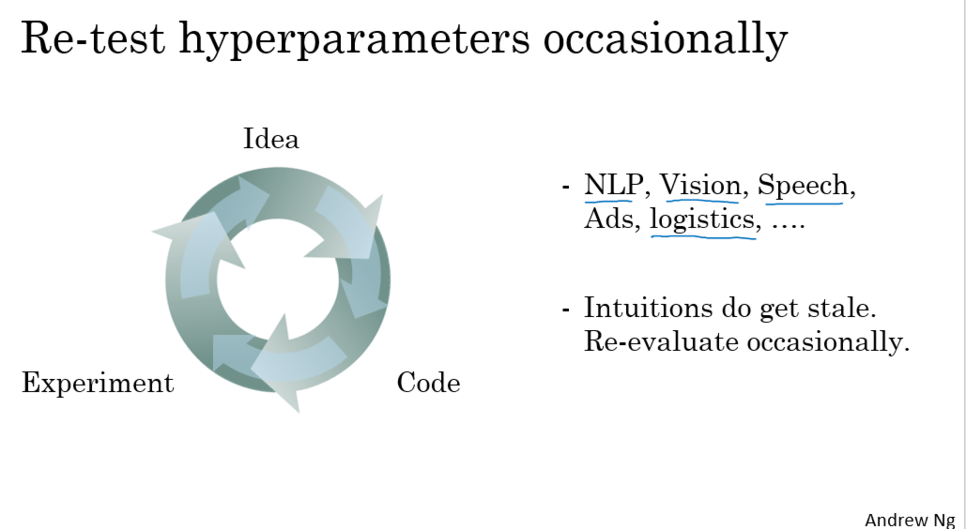
3. 실전에서 hyperparameter 서칭방식(Pandas vs Caviar)
1. babysit 방식 (panda approach)
아주 큰 데이터가 있고 산출 자원은 많이 없을 때 적용
* 산출 자원
산출자원이라 하면 CPU나 GPU같은것이 많이 없어 1가지 모델만 트레이닝할 여건일 경우
아주 작은 수의 모델만 한번에 트레이닝 시킬 수 밖에 없는 경우
* 이름 유래
panda가 아이를 갖는 경우, 굉장히 조금 갖음. 한번에 1명씩. 그 아기의 생존에 최선
2. parallel 방식(caviar approach)
여러 모델을 트레이닝 시키는 방법
충분히 많은 컴퓨터를 가지고 있어 여러개의 모델 학습 가능하면 적용
* 이름 유래
물고기는 1시즌에 1억개가 넘는 생선알 낳음
1억개 일일히 신경쓰지 않고 1억개 중 소수가 잘 되어 생존하기를 원함.
=> 얼마나 산출 자원을 가지고 있느냐에 따라 선택 달라짐.

'데이터과학 > 개념 : Deep Learning' 카테고리의 다른 글
| [딥러닝 기본] ML Strategy 2 (0) | 2022.04.01 |
|---|---|
| [딥러닝 기본] ML Strategy 1 (human-level performance) (0) | 2022.04.01 |
| [딥러닝 기본] Deep Learning 학습최적화 셋팅 (0) | 2022.03.28 |
| [딥러닝 기본] Setting up your ML application (0) | 2022.03.28 |
| [딥러닝 기본] Deep learning 학습개념 2 (0) | 2022.03.28 |



