
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 하둡
- 빅데이터
- 자연어처리
- R시각화
- R그래프
- AI
- 기계학습
- R프로그래밍
- 빅데이터처리
- 데이터시각화
- word2vec
- ggplot
- CNN
- lstm
- 머신러닝
- 주가예측
- pandas
- 데이터
- Hadoop
- SQL
- NLP
- 데이터분석
- 딥러닝
- Python
- r
- 그래프시각화
- HIVE
- 그래프
- 데이터처리
- Deeplearning
- Today
- Total
욱이의 냉철한 공부
[딥러닝 기본] ML Strategy 1 (human-level performance) 본문
* 출저
본 개념정리는 제 지도교수님이신 연세대학교 정보대학원 김하영 교수님 수업과 Andrew 교수님의 Coursera 수업을 통해 얻은 정보를 통해 정리했습니다. 자료는 대부분 Andrew 교수님의 Coursera 수업자료입니다.


1. Introduction to ML Strategy
1) Why ML Strategy?

2) Orthogonalization


2. Setting up your goal
1). Single number evaluation metric
- idea – code – experiment
- 다양한 평가지표
평가지표 : Precision, Recall
새로운 평가지표 : F1 score
또 다른 방법 : 알고리즘 대륙 전체 평균


2). Satisficing and Optimizing metric
- Satisficing(최소한의 충족) + optimizing(최적화)
ex) 종합 평가 수치 = 러닝타임 + 정확도

3) Train, dev, test distributions
- 무작위로 섞인 데이터 분포도 활용해야 한다.

- 같은 분포도를 가지는 Train, dev 활용
train, dev 같은 목표를 타깃 해야 한다.
dev set 설정하는 방법과 validation metric 중요.
어떠한 목표를 타깃하는지 정의


- 어떻게 트레이닝 세트를 설정하는가에 따라서 얼마나 잘 목표를 맞추는지 결정 가능.
ex) 저소득층, 고소득층 데이터 활용 x
4) Size of the dev and test sets.
- 많은 데이터 셋을 가지는 경우 : 98% 트레이닝 세트, 1% dev, 1% 테스트로 분배가 합리적.
큰 데이터 세트를 보유하고 있는 것에 대한 문제점이 상당부분 트레이닝 세트로 이전
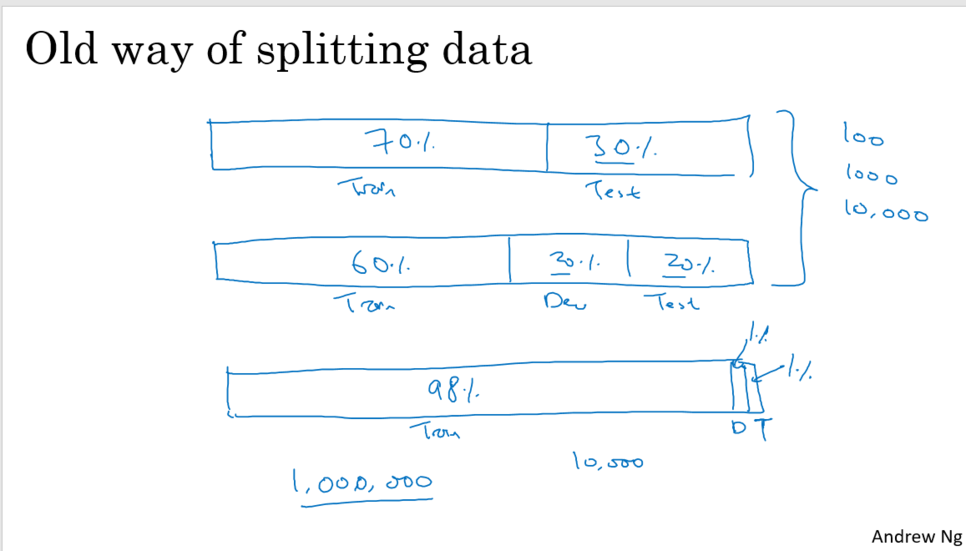
- size of test set 유연하게 조절
테스트 세트의 목적은 시스템 개발을 마친 이후로는, 테스트 세트가 마지막 시스템이 얼마 나 좋은지 평가하는데 도움
테스트 세트를 적당히 크게 하여 전반적인 시스템의 성능의 컨피던스 레벨이 높을 수 있도 록 하는 것
그렇기 때문에 마지막 최후 시스템이 얼마나 잘 작동하는지 매우 자세히 알아야 하는 것이 아니라고 하면 수백만 개의 example이 필요치 않을 것


5) When to change dev/test sets and metrics
- metric change 개요
dev set와 평가 매트릭 지표를 세팅하는 것은 팀이 목표를 지향할 수 있도록 방향성을 제시하는 것과 같다.
하지만 프로젝트 진행도중에 잘못된 방향이었다는 것을 뒤늦게 깨닫는 경우도 있다.
이런 경우엔, 목표를 이동해야 한다.
오류 있을 경우 새로운 매트릭(목표)를 정의해야한다.
ex) 성능이 좋은 A알고리즘에 오류값에 포르노 사진이 있다면? : 잘못된 알고리즘
=> 새로운 매트릭 정의 필요 : 포르노 사진에 가중치를 더 두는 손실함수 설정 필요)

- metric change 단계
1단계 : 목표 설정 (매트릭 정의)
2단계 : 튜닝 (어떻게 하면 이 메트릭이 성능을 잘 발휘할지 생각)

- dev/test sets change 개요
고품질 이미지로 알고리즘 구현했지만 실제 어플에서는 저품질 이미지 사용?
=> 데이터 셋을 변경할 필요가 있다.

3. Comparing to human-level performance
1). Why human level performance?
- 머신러닝 시스템 vs 인간레벨 시스템
첫째 : 딥러닝의 발전으로, 머신러닝 알고리즘 잘 구동.
인간레벨 서능과 비교했을 때, 이와 견줄만한 정도로 알고리즘 실효성 입증
둘째 : 인간이 할 수 있는 영역에서, 머신러닝 시스템을 디자인하고 수행절차 설립과정 이전에 비해 효율적으로 발전.
(시스템 발전 등)
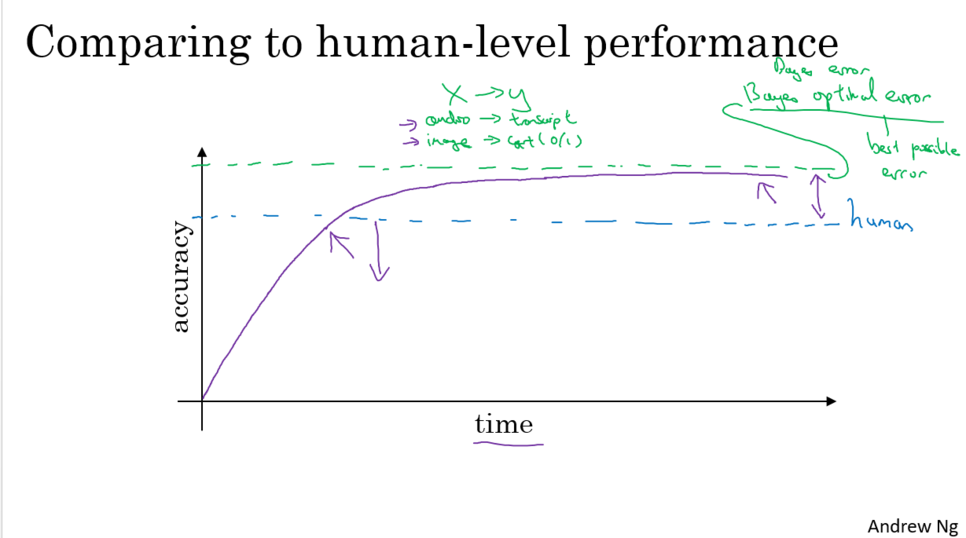
- Bayes error (Bayes optimal error)
어떤 오디오는 너무 시끄러워서 어떤 내용이 들어있는지 판단 불가
어떤 이미지는 너무 흐릿하여 이미지가 고양이 사진인지 판단 불가
=> 이런 오류들 다 제외한 오류가 Bayes error
- 정확도는 인간레벨성능을 능가한 이후로 느려짐.
1. 인간레벨성능이 Bayes error와 많이 떨어져 있지 않다.
(인간은 보통 이미지를 구분하고 고양이인지 여부를 확인하는데 능숙, 오디오를 들어서 표기화 하는 것에 능숙)
=> 인간레벨성능을 이미 능가한 시점에서는 더 발전할 수 있는 부분 제한적
2. 인간레벨성능에 미치지 못하는 이상, 여러 가지 툴을 이용하여 성능을 발달시킬 수 있는 부분 있다.
하지만 인간레벨성능 초과시점부터는 사용하기 어렵.
=> 인간이 잘 수행하는 업무 : 인간으로부터 labeled data 습득 가능
=> 인간이 알고리즘보다 더 능숙한 성능 : 인간에게 물어봐 통찰력 기를 수 있다.
=> 편향, 편차

2) Avoidable bias


- 1. 사례 : 인간레벨성능 1% 오류 (ex)고양이 인식 프로그램)
트레이닝 오류 : 8%
dev 오류 : 10%
트레이닝 세트에서의 알고리즘 성능과 인간의 차이가 매우 큼
트레이닝 세트에서 잘 피팅되고 있지 않다. => Bias 문제에 중점
=> 해결안 : 더 큰 신경망 트레이닝 하거나 더 오래 동안 학습.
- 2. 사례 : 인간레벨 성능 7.5% 오류 (ex)고양이이미지가 너무 흐리거나 품질 이상)
트레이닝 오류 : 8%
dev 오류 : 10%
트레이닝 세트에서의 알고리즘 성능과 인간의 차이가 매우 작음 => variance 문제에 중점
=> 해결안 : 일반화 시도

- 인간레벨오류를 Bayes error의 추정치로 생각
컴퓨터비젼 영역에서는 매우 합리적인 프록시 값.
사람이 컴퓨터 비전영역에서 능숙하기에
그리고 대부분 인간레벨오류는 Bayes error에 크게 떨어져 있지 않다.
- avoidable bias
Bayes error 또는 Bayes error(인간레벨오류)의 근사치와 트레이닝 오류의 차이
avoidable bias는 용어 자체가 최소의 오류 값이나 특정 오류가 있다는 것을 인정
Bayes error는 7.5퍼센트인 경우 이 이하로 내려갈 수 없다는 뜻도 내포
=> 트레이닝 오류가 8퍼센트라고 이야기하기 보다는, 8퍼센트는 바이어스의 측정수치
해당 예시에서는 avoidable bias가 0.5퍼센트이거나, 2퍼센트는 편차 수치
3) Understanding human-lavel performance
- 사례
0.7% 오류에 도달했을 때, Bayes error를 추정하는데 신경 쓰지 않는 이상, Bayes error에서 얼마나 떨어져 있는지 알기 어렵. (의사팀인 0.5%를 기반으로 Bayes error를 추정해야 avoidable bias 측정 가능)
그러므로 avoidable bias를 얼마나 줄여야 할지도 모른다.
=> 인간라벨성능과 가까운 선상에 있는 경우, 바이어스와 편차효과를 제거하기가 굉장히 더 어렵.
결과적으로는 더 잘하면 잘할수록 머신러닝에서 발전을 이루기가 점진적으로 어렵

- 정리
1) 인간레벨성능의 추정치를 알면 Bayes error의 예상 값을 알 수 있음
2) 알고리즘에서 바이어스의 값을 줄일지, 편차 값을 줄일지 의사결정
=> 이런 테크닉은 인간레벨성능을 도달하기 전까지는 잘 작동
이후로는 Bayes error 추정 값이 구하기 어렵기 때문에 의사결정을 내리는데 어려움


4) Surpassing human-level performance
- 사례 (인간레벨성능을 뛰어넘는 사례)
1. 온라인 광고 (한 사람이 광고를 클릭할 확률)
2. 영화나 책 추천.
3. A지점에서 B까지 운전하여 이동하는데 얼마나 걸릴지 예측
4. 대출금을 갚을 확률
=> 이러한 유형의 특성은 구조화된 데이터를 기반.(데이터베이스를 기반)
자연적으로 인지되는 문제들 아니다. (컴퓨터의 영역, 음성인식, 자연처리)
=> 아주 방대한 데이터 양 보유.
인간이 볼 수 있는 데이터 양보다 훨씬 더 많이 조회
이런 부분이 컴퓨터가 그래도 어느 정도 쉽게 인간레벨 따라 잡을 수 있는 요소
- 단점
컴퓨터가 조사할 수 있는 데이터가 너무 많으므로 그래서 그것은 심지어 인간의 생각도 패턴화하며 왜곡
- 전망
최근에는 음성인식분야에서도 인간레벨성능을 뛰어넘는 수준.
컴퓨터 영역과, 이미지 인식 업무도 마찬가지로, 인간레벨성능을 뛰어 넘고 있음.
사실 인간은 자연적으로 인식하는 업무에 굉장히 뛰어나기 때문에, 컴퓨터가 현재자리까지 도달하기 어려웠던 부분 많음.
하지만 충분한 데이터양 확보된다면 지도학습 분야에서 인간레벨성능을 뛰어넘는 경우 많아질 것.


5) Imporving your model performance


'데이터과학 > 개념 : Deep Learning' 카테고리의 다른 글
| [딥러닝 기본] Transfer learning (전이 학습) (2) | 2022.04.01 |
|---|---|
| [딥러닝 기본] ML Strategy 2 (0) | 2022.04.01 |
| [딥러닝 기본] Hyperparameter tuning : 하이퍼파라미터 튜닝 (0) | 2022.03.28 |
| [딥러닝 기본] Deep Learning 학습최적화 셋팅 (0) | 2022.03.28 |
| [딥러닝 기본] Setting up your ML application (0) | 2022.03.28 |



