
욱이의 냉철한 공부
[딥러닝 기본] Transfer learning (전이 학습) 본문
1. Transfer learning 개념
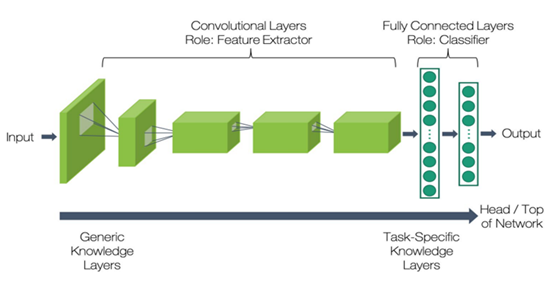
적은 이미지 데이터 세트에서 딥러닝을 적용하기 위한 효과적인 방법은 전이학습이다. 전이학습은 높은 정확도를 비교적 짧은 시간 내에 달성할 수 있게 해주기 때문에 컴퓨터 비전 분야에서 널리 쓰이는 방법론이다. 일반적으로 대규모 이미지 데이터 세트에서 사전 훈련된 DCNN 모델을 새로운 task에 적합하도록 수정하여 활용한다. 그림 10과 같이 기존 DCNN 모델에서는 하위계층이 일반적인 특징을 추출하도록 학습이 이루어지고, 상위계층은 특정 문제에서만 나타날 수 있는 구체적인 특징을 추출하도록 학습되어 졌다. 전이학습 시 하위계층들은 일반적으로 재사용될 수 있지만, 상위계층은 데이터 크기와 유사성에 따라 재학습이 필요하다.
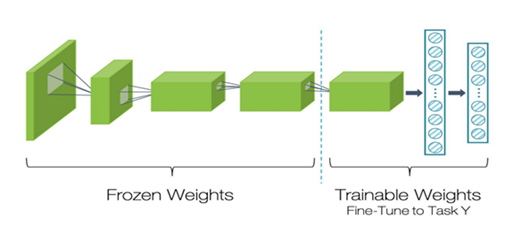
전이학습을 진행하는 방법은 그림 11처럼 4가지 경우로 분류된다.
첫째는 새로운 문제의 데이터 크기가 크고 사전 학습된 데이터와 유사성이 적은 경우이다. 이 경우는 사전학습된 모델의 구조만 사용하면서, 전체 파라미터를 새로운 데이터에 재학습시키는 방법이 적합하다. 기존 사전학습된 모델의 하위계층에서 추출한 일반적인 특징이 새로운 데이터 세트에서 추출할 특징과 차이가 클 수 있기 때문이다.
둘째는 새로운 문제의 데이터 크기가 크고 사전 학습된 데이터와 유사성이 높은 경우이다. 이 경우는 상위계층의 일부분만 새로운 데이터에 재학습시키는 방법이 적합하다. 데이터의 유사성이 높아서 사전 학습된 모델의 일반적인 정보를 최대한 활용하는 것이 효과적이다. 또한, 데이터 세트가 크기 때문에 과적합 문제를 최소화할 수 있어 필요한 파라미터만 재학습시킬 수 있다.
셋째는 새로운 문제의 데이터 크기가 작고 사전 학습된 데이터와 유사성도 적은 경우이다. 이 경우에는 그림 12처럼 재학습시킬 적절한 계층의 수를 찾아야 한다. 너무 많은 계층을 새로 학습시키면 작은 데이터 세트에 모델이 과적합 될 우려가 있고, 너무 적은 계층만을 학습시키면 모델은 제대로 학습되지 않을 것이다. 더불어 작은 크기의 데이터 세트를 보완하기 위해 데이터 증강 기법처럼 과적합 방지 기술이 함께 필요하게 된다.
넷째는 새로운 문제의 데이터 크기가 작지만, 사전 학습된 데이터와 유사성은 높은 경우이다. 이 경우에는 그림 13처럼 사전학습된 모델의 마지막 부분인 분류기만 제거하고 특징 추출기는 모두 재사용한다. 새로운 분류기만 학습함으로써, 기존의 추출된 특징들을 그대로 사용하는 것이다.


2. EX) 논문 리비전 할 때 Transfer learning 관련 답변서
For the comparison, typically the pretrained transformers outperform the normal model like CNN/LSTM. The authors should introduce more about their setups of baselines: were the models fine-tuned? how were the model fine-tuned? only the final layer was fine-tuned or the whole? ...
우리는 사전 훈련된 언어 모델(LM)에 대한 기준 설정의 세부 사항을 자세히 설명해야 한다는 데 동의합니다.
그림 R1.(c)에서 볼 수 있듯이 매우 작은 학습률로 전체 모델을 미세 조정했습니다. 더 구체적으로 말하자면, 큰 LM에 대한 사전 훈련된 지식을 유지하고 과적합을 피하기 위해 모델은 3e-5의 작은 학습률과 32개의 미니 배치로 30개의 에포크에 대해 미세 조정되었습니다. β1 = 0.9, β2 = 0.999, ε = 1e–8인 Adam 최적화기는 모든 변압기 기반 LM에 대해 고려되었습니다. 수정된 원고에서 이러한 기준 설정을 명시적으로 설명했습니다.
그림 R1과 같이 LM을 최적화하기 위해 세 가지 방법으로 미세 조정 실험을 수행했습니다. 이러한 실험에 대한 교육 세부 정보는 표 R2에 나와 있습니다. 표 R1은 전체 모델의 미세 조정이 최고의 성능을 달성했음을 보여줍니다(그림 R1(c)). 특히 전체 모델을 미세 조정하면 최종 레이어만 미세 조정하는 것보다 더 나은 결과를 얻을 수 있습니다. 따라서 사전 훈련된 전체 LM을 원고에 미세 조정한 결과를 제시했습니다.
좀 더 자세하게는 임베딩 레이어를 포함한 전체 모델을 동결하고 분류 레이어(최종 레이어)만 미세 조정한 경우(그림 R1(a)) 성능이 좋지 않았다. 그러나 임베딩 레이어도 학습되었을 때(그림 R1(b)), 임베딩 레이어가 동결되었을 때(그림 R1(a))에 비해 상대적으로 높은 성능 향상이 발생했습니다. 사전 훈련된 데이터셋(위키피디아)과 달리 결함 텍스트에 있는 대부분의 단어가 빌딩 관리에 특화된 기술 용어(전문용어)로 구성되어 임베딩 레이어를 미세 조정한 결과가 더 좋았다고 생각합니다. 또한 데이터 세트와 작업이 모두 다르기 때문에(다음 단어 예측 대 결함 분류) 전체 모델을 미세 조정하는 성능을 최고로 만들 수 있습니다.
귀하가 언급했듯이 변압기 기반 대형 LM은 일반적으로 기본 CNN/LSTM 접근 방식을 능가합니다. 변압기 기반 LM은 많은 매개변수로 상당한 표현력을 갖기 때문입니다. 그러나 최적의 네트워크 아키텍처는 작업의 난이도와 샘플 수에 따라 다릅니다(Shorten & Khoshgoftaar, 2019). 따라서 작업의 복잡성과 샘플 수에 비해 너무 큰 신경망을 설계하면 과적합되기 쉽습니다. 특히 사전 훈련된 LM을 미세 조정할 때 데이터 샘플의 수가 중요합니다. 본 연구에서 건물 결함 텍스트 데이터 세트의 샘플 수는 16,106개에 불과하며 각 샘플은 평균 15개의 토큰( BertTokenizer 사용). 우리의 과제는 기술 용어와 매우 짧은 텍스트로 인해 도전적이지만 텍스트 분류와 유사한 작업 수준이며 LM이 일반적으로 해결하는 기계 번역 및 질문 답변만큼 어렵지 않습니다. Shin et al. (2021), 작업이 상대적으로 간단하고 데이터 수가 적기 때문에 더 적은 수의 매개변수를 사용하여 효율적으로 설계된 모델이 과적합을 방지하면서 큰 LM을 능가할 수 있습니다. Shinet al. (2021) CNN-Word2Vec은 건강 진단 텍스트를 사용하여 갑상선 상태를 자동으로 분류하는 데 LM ELECTRA보다 더 높은 F1 점수를 달성했다고 보고했습니다. CNN은 로컬 연결성 및 가중치 공유로 인해 매개변수가 적고 필터 및 깊이를 통해 로컬 및 글로벌 관계(토큰과 컨텍스트 간의 관계)를 캡처할 수 있어 문장 분류(Y. Kim)와 같은 비교적 쉬운 작업에 대해 좋은 성능을 보입니다. , 2014; Conneau et al., 2016). 이러한 CNN의 특성과 작업을 고려하여 CNN 기반 AutoDefect 모델을 개발했습니다.

| Model | Task average | Average F1-score [%] | ||||
| Work | Location | Defect | Element | |||
| (a) Training only the classifier | BERT (multilingual-cased) |
54.74 | 40.30 | 66.36 | 60.15 | 52.16 |
| BERT | 20.63 | 15.11 | 32.61 | 20.48 | 14.33 | |
| ELECTRA | 28.30 | 15.72 | 44.40 | 34.92 | 18.17 | |
| GPT2 | 43.14 | 21.52 | 76.98 | 40.96 | 33.12 | |
| (b) Fine-tuning only the classifier and embedding layer | BERT (multilingual-cased) |
87.69 | 87.70 | 93.00 | 84.31 | 85.76 |
| BERT | 86.70 | 85.81 | 91.77 | 83.22 | 85.98 | |
| ELECTRA | 84.75 | 81.88 | 91.13 | 81.21 | 84.76 | |
| GPT2 | 84.83 | 83.35 | 90.69 | 82.08 | 83.19 | |
| (c) Fine-tuning all layers of the whole model | BERT (multilingual-cased) |
89.39 | 88.04 | 94.29 | 86.93 | 88.28 |
| BERT | 89.62 | 88.12 | 93.80 | 86.07 | 90.47 | |
| ELECTRA | 89.47 | 89.71 | 93.51 | 86.18 | 88.49 | |
| GPT2 | 89.68 | 89.19 | 93.55 | 85.52 | 90.46 | |
| AutoDefect (FastText+Word2Ve) |
90.72 | 90.08 | 93.74 | 87.05 | 92.02 | |
Table R1. Results of fine-tuning experiments on pre-trained language models
Table R2. Training details of fine-tuning experiments on pre-trained language models
| Training details | |||||
| Optimizer | Epoch | Batch size | Initial learning rate |
learning rate decay scheduling | |
| (a) Training only the classifier | Adam | 50 | 32 | 3e-4 | 0.2 decay factor 6 epochs patience |
| (b) Fine-tuning only the classifier and embedding layer | Adam | 50 | 32 | 3e-4 | 0.2 decay factor 10 epochs patience |
| (c) Fine-tuning all layers of the whole model | Adam | 30 | 32 | 3e-5 | fixed learning rate |
| AutoDefect (FastText+Word2Ve) |
Adam | 30 | 32 | 1e-3 | 0.2 decay factor 2 epochs patience |
'데이터과학 > 개념 : Deep Learning' 카테고리의 다른 글
| [딥러닝 기본] ML Strategy 2 (0) | 2022.04.01 |
|---|---|
| [딥러닝 기본] ML Strategy 1 (human-level performance) (0) | 2022.04.01 |
| [딥러닝 기본] Hyperparameter tuning : 하이퍼파라미터 튜닝 (0) | 2022.03.28 |
| [딥러닝 기본] Deep Learning 학습최적화 셋팅 (0) | 2022.03.28 |
| [딥러닝 기본] Setting up your ML application (0) | 2022.03.28 |



